实时电商
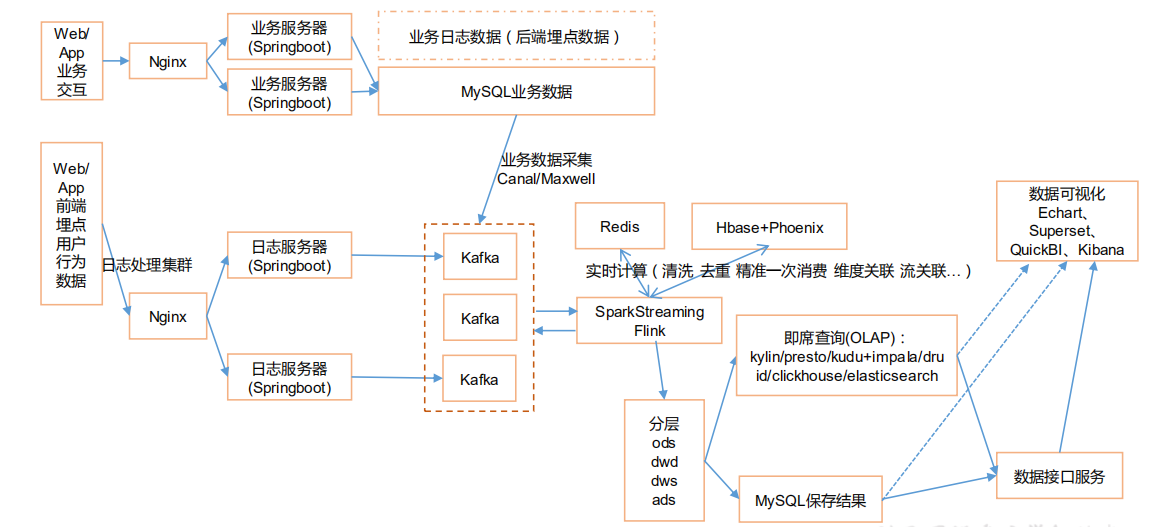
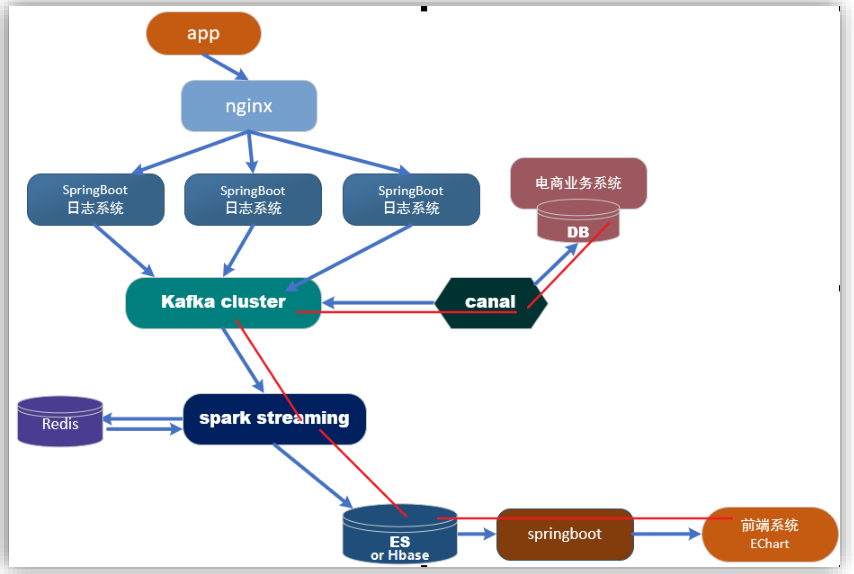
# 项目实时架构
# 项目数据准备
# 模拟日志生成器的使用
- 创建rt_applog 目录
- 将文件上传到文件夹下
- 修改application.properties文件
- 使用模拟日志生成器的 jar 运行
# 将生成数据存储到kafka中
创建工程并导入相关依赖
代码
@RestController @Slf4j public class LoggerController { //Spring提供的对Kafka的支持 @Autowired // 将KafkaTemplate注入到Controller中 KafkaTemplate kafkaTemplate; //http://localhost:8080/applog //提供一个方法,处理模拟器生成的数据 //@RequestMapping("/applog") 把applog请求,交给方法进行处理 //@RequestBody 表示从请求体中获取数据 @RequestMapping("/applog") public String applog(@RequestBody String mockLog){ //System.out.println(mockLog); //落盘 log.info(mockLog); //根据日志的类型,发送到kafka的不同主题中去 //将接收到的字符串数据转换为json对象 JSONObject jsonObject = JSON.parseObject(mockLog); JSONObject startJson = jsonObject.getJSONObject("start"); if(startJson != null){ //启动日志 kafkaTemplate.send("gmall_start_0523",mockLog); }else{ //事件日志 kafkaTemplate.send("gmall_event_0523",mockLog); } return "success"; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34修改日志生成后发送地址
启动服务查看订阅topic信息
bin/kafka-console-consumer.sh --bootstrap-server ha01:9092 --topic gmall_start_05231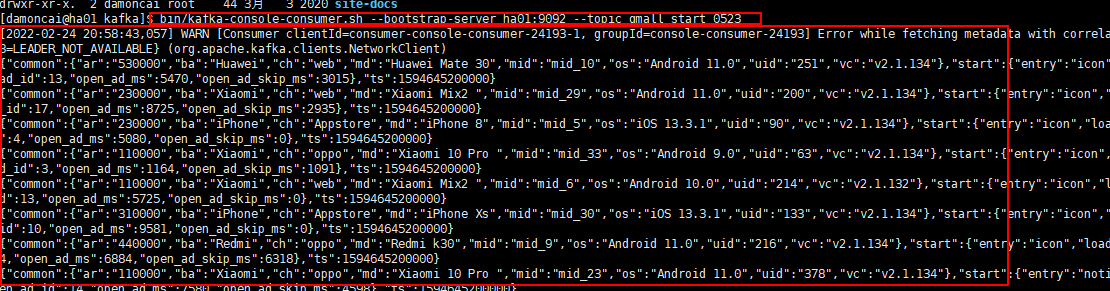
# ES知识
# 日活
从项目的日志中获取用户的启动日志,如果是当日第一次启动,纳入统计。将统计结果保存到 ES 中,利用 Kibana 进行分析展示
# 功能实现
# 开发环境
配置信息
- config.properties
# Kafka 配置 kafka.broker.list=ha01:9092,ha02:9092,ha03:9092 # Redis 配置 redis.host=192.168.111.17 redis.port=6379 redis.password=prinfo1
2
3
4
5
6log4j.properties
log4j.appender.damoncai.MyConsole=org.apache.log4j.ConsoleAppender log4j.appender.damoncai.MyConsole.target=System.out log4j.appender.damoncai.MyConsole.layout=org.apache.log4j.PatternLayout log4j.appender.damoncai.MyConsole.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %10p (%c:%M) - %m%n log4j.rootLogger =error,damoncai.MyConsole1
2
3
4
5
pom文件
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <spark.version>3.0.0</spark.version> <scala.version>2.12.11</scala.version> <kafka.version>2.4.1</kafka.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.62</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>${kafka.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> <dependency> <groupId>io.searchbox</groupId> <artifactId>jest</artifactId> <version>5.3.3</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.11.0</version> </dependency> <dependency> <groupId>net.java.dev.jna</groupId> <artifactId>jna</artifactId> <version>4.5.2</version> </dependency> <dependency> <groupId>org.codehaus.janino</groupId> <artifactId>commons-compiler</artifactId> <version>3.0.16</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>6.6.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.6</version> <executions> <execution> <!-- 声明绑定到 maven 的 compile 阶段 --> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
# 读取 properties 配置文件的工具类 - MyPropertiesUtil
object MyPropertiesUtil {
/**
* 测试
*/
def main(args: Array[String]): Unit = {
val properties: Properties = load(" config.properties")
println(properties)
}
def load(propertieName: String): Properties = {
val prop = new Properties()
prop.load(
new InputStreamReader(
Thread.currentThread().getContextClassLoader.getResourceAsStream(propertieName) ,
"UTF-8"
)
)
prop
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 读取 Kafka 消息的工具类 - MyKafkaUtil
object MyKafkaUtil {
private val properties:Properties = MyPropertiesUtil.load(" config.properties")
val broker_list = properties.getProperty("kafka.broker.list")
// kafka 消费者配置参数
var kafkaParam = collection.mutable.Map(
"bootstrap.servers" -> broker_list,//用于初始化链接到集群的地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
//用于标识这个消费者属于哪个消费团体
"group.id" -> "gmall2020_group",
//latest 自动重置偏移量为最新的偏移量
"auto.offset.reset" -> "latest",
//如果是 true,则这个消费者的偏移量会在后台自动提交,但是 kafka 宕机容易丢失数据
//如果是 false,会需要手动维护 kafka 偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)
)
// 创建 DStream,返回接收到的输入数据
def getKafkaStream(topic: String, ssc: StreamingContext) : InputDStream[ConsumerRecord[String,String]] = {
val dStream = KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Array(topic),kafkaParam)
)
dStream
}
def getKafkaStream(topic: String,ssc:StreamingContext,offsets:Map[TopicPartition,Long],groupId:String): InputDStream[ConsumerRecord[String,String]]={
kafkaParam("group.id")=groupId
val dStream = KafkaUtils.createDirectStream[String,String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String,String](Array(topic),kafkaParam,offsets))
dStream
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 获取 Redis 连接的工具类 - MyRedisUtil
object MyRedisUtil {
var jedisPool:JedisPool=null
def getJedisClient: Jedis = {
if(jedisPool == null) {
val config = MyPropertiesUtil.load("config.properties")
val host = config.getProperty("redis.host")
val port = config.getProperty("redis.port")
val password = config.getProperty("redis.password")
val jedisPoolConfig = new JedisPoolConfig()
jedisPoolConfig.setMaxTotal(100) //最大连接数
jedisPoolConfig.setMaxIdle(20) //最大空闲
jedisPoolConfig.setMinIdle(20) //最小空闲
jedisPoolConfig.setBlockWhenExhausted(true) //忙碌时是否等待
jedisPoolConfig.setMaxWaitMillis(5000)//忙碌时等待时长 毫秒
jedisPoolConfig.setTestOnBorrow(true) //每次获得连接的进行测试
jedisPool=new JedisPool(jedisPoolConfig,host,port.toInt,3000,password)
}
jedisPool.getResource
}
/**
* 测试
*/
def main(args: Array[String]): Unit = {
val jedisClient = getJedisClient
println(jedisClient.ping())
jedisClient.close()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 测试 - SparkStreaming消费kafka中的数据
object DauApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("dau_app")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "gmall_dau_bak"
val topic = "gmall_start_0523"
val recordDstream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
val jsonObjDStream: DStream[JSONObject] = recordDstream.map { record =>
//获取启动日志
val jsonStr: String = record.value()
//将启动日志转换为 json 对象
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
//获取时间戳 毫秒数
val ts: lang.Long = jsonObj.getLong("ts")
//获取字符串 日期 小时
val dateHourString: String = new SimpleDateFormat("yyyy-MM-dd HH").format(new Date(ts))
//对字符串日期和小时进行分割,分割后放到 json 对象中,方便后续处理
val dateHour: Array[String] = dateHourString.split(" ")
jsonObj.put("dt",dateHour(0))
jsonObj.put("hr",dateHour(1))
jsonObj
}
//测试输出 2
jsonObjDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
启动 Zookeeper
启动 Kafka
启动 logger.sh(日志处理服务-Nginx 和 SpringBoot 程序)
Idea 中运行程序
运行模拟生成日志的 jar
查看IDEA控制台输出

# 利用 Redis 过滤当日已经计入的日活设备
val jsonObjDStream: DStream[JSONObject] = recordDstream.map { record =>
//获取启动日志
val jsonStr: String = record.value()
//将启动日志转换为 json 对象
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
//获取时间戳 毫秒数
val ts: lang.Long = jsonObj.getLong("ts")
//获取字符串 日期 小时
val dateHourString: String = new SimpleDateFormat("yyyy-MM-dd HH").format(new Date(ts))
//对字符串日期和小时进行分割,分割后放到 json 对象中,方便后续处理
val dateHour: Array[String] = dateHourString.split(" ")
jsonObj.put("dt",dateHour(0))
jsonObj.put("hr",dateHour(1))
jsonObj
}
val filteredDStream: DStream[JSONObject] = jsonObjDStream.mapPartitions {
jsonObjItr => {
//获取 Redis 客户端
val jedisClient: Jedis = MyRedisUtil.getJedisClient
//定义当前分区过滤后的数据
val filteredList: ListBuffer[JSONObject] = new ListBuffer[JSONObject]
for (jsonObj <- jsonObjItr) {
//获取当前日期
val dt: String = jsonObj.getString("dt")
//获取设备 mid
val mid: String = jsonObj.getJSONObject("common").getString("mid")
//拼接向 Redis 放的数据的 key
val dauKey: String = "dau:" + dt
//判断 Redis 中是否存在该数据
val isNew: lang.Long = jedisClient.sadd(dauKey,mid)
//设置当天的 key 数据失效时间为 24 小时
jedisClient.expire(dauKey,3600*24)
if (isNew == 1L) {
//如果 Redis 中不存在,那么将数据添加到新建的 ListBuffer 集合中,实现过滤的效果
filteredList.append(jsonObj)
}
}
jedisClient.close()
filteredList.toIterator
}
}
//输出测试 数量会越来越少,最后变为 0 因为我们 mid 只是模拟了 50 个
filteredDStream.count().print()
ssc.start()
ssc.awaitTermination()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
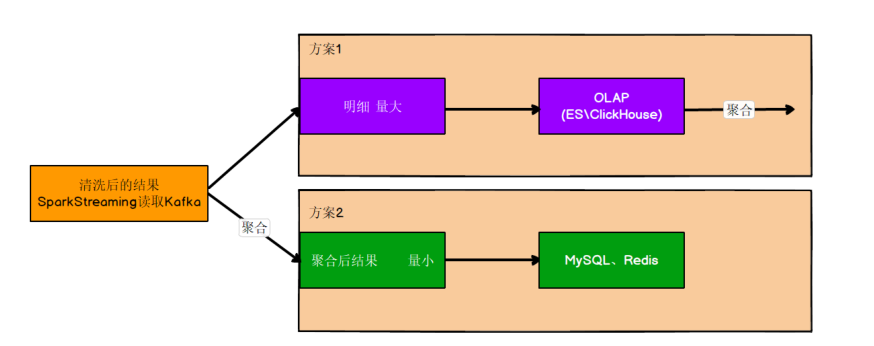
# 保存到ES中
在ES中创建模板
PUT _template/gmall2020_dau_info_template { "index_patterns": ["gmall2020_dau_info*"], "settings": { "number_of_shards": 3 }, "aliases" : { "{index}-query": {}, "gmall2020_dau_info-query":{} }, "mappings": { "_doc":{ "properties":{ "mid":{ "type":"keyword" }, "uid":{ "type":"keyword" }, "ar":{ "type":"keyword" }, "ch":{ "type":"keyword" }, "vc":{ "type":"keyword" }, "dt":{ "type":"keyword" }, "hr":{ "type":"keyword" }, "mi":{ "type":"keyword" }, "ts":{ "type":"date" } } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45ES批插入数据封装
//向 ES 中批量插入数据 //参数 1:批量操作的数据 参数 2:索引名称 def bulkInsert(sourceList:List[Any],indexName:String): Unit = { if (sourceList != null && sourceList.size > 0) { //获取操作对象 val jest: JestClient = getClient //构造批次操作 val bulkBuild: Bulk.Builder = new Bulk.Builder //对批量操作的数据进行遍历 for (source <- sourceList) { val index: Index = new Index.Builder(source) .index(indexName) .`type`("_doc") .build() //将每条数据添加到批量操作中 bulkBuild.addAction(index) } //Bulk 是 Action 的实现类,主要实现批量操作 val bulk: Bulk = bulkBuild.build() //执行批量操作 获取执行结果 val result: BulkResult = jest.execute(bulk) //通过执行结果 获取批量插入的数据 val items: util.List[BulkResult#BulkResultItem] = result.getItems println("保存到 ES" + items.size() + "条数") //关闭连接 jest.close() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28编写插入逻辑
// 向ES中插入数据 filteredDStream.foreachRDD{ rdd=>{//获取 DS 中的 RDD rdd.foreachPartition{//以分区为单位对 RDD 中的数据进行处理,方便批量插入 jsonItr=>{ val dauList: List[DauInfo] = jsonItr.map { jsonObj => { //每次处理的是一个 json 对象 将 json 对象封装为样例类 val commonJsonObj: JSONObject = jsonObj.getJSONObject("common") DauInfo( commonJsonObj.getString("mid"), commonJsonObj.getString("uid"), commonJsonObj.getString("ar"), commonJsonObj.getString("ch"), commonJsonObj.getString("vc"), jsonObj.getString("dt"), jsonObj.getString("hr"), "00", //分钟我们前面没有转换,默认 00 jsonObj.getLong("ts") ) } }.toList //对分区的数据进行批量处理 //获取当前日志字符串 val dt: String = new SimpleDateFormat("yyyy-MM-dd").format(new Date()) ESUtil.bulkInsert(dauList,"gmall2020_dau_info_" + dt) } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 保证数据的精准一次性消费
数据何时会丢失
比如实时计算任务进行计算,到数据结果存盘之前,进程崩溃,假设在进程崩溃前 kafka调整了偏移量,那么 kafka 就会认为数据已经被处理过,即使进程重启,kafka 也会从新的偏移量开始,所以之前没有保存的数据就被丢失掉了。
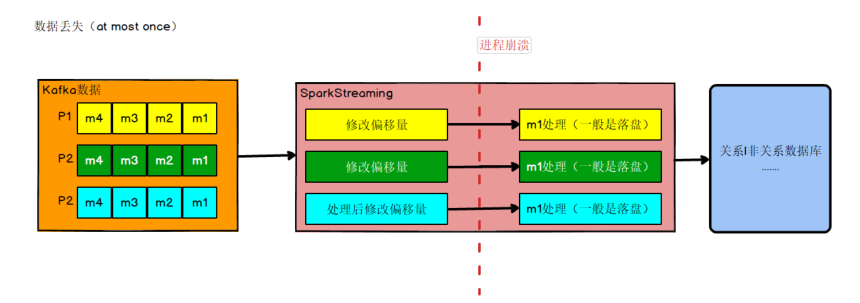
如果数据计算结果已经存盘了,在 kafka 调整偏移量之前,进程崩溃,那么 kafka 会认为数据没有被消费,进程重启,会重新从旧的偏移量开始,那么数据就会被 2 次消费,又会被存盘,数据就被存了 2 遍,造成数据重复。
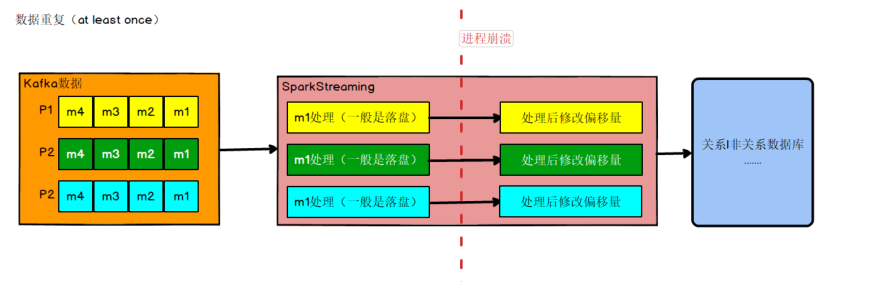
如果同时解决了数据丢失和数据重复的问题,那么就实现了精确一次消费的语义了
目前 Kafka 默认每 5 秒钟做一次自动提交偏移量,这样并不能保证精准一次消费enable.auto.commit 的默认值是 true;就是默认采用自动提交的机制。 auto.commit.interval.ms 的默认值是 5000,单位是毫秒。
如何解决
策略一
出现丢失或者重复的问题,核心就是偏移量的提交与数据的保存,不是原子性的。如果能做成要么数据保存和偏移量都成功,要么两个失败,那么就不会出现丢失或者重复了。 这样的话可以把存数据和修改偏移量放到一个事务里。这样就做到前面的成功,如果后面做失败了,就回滚前面那么就达成了原子性,这种情况先存数据还是先修改偏移量没影响。
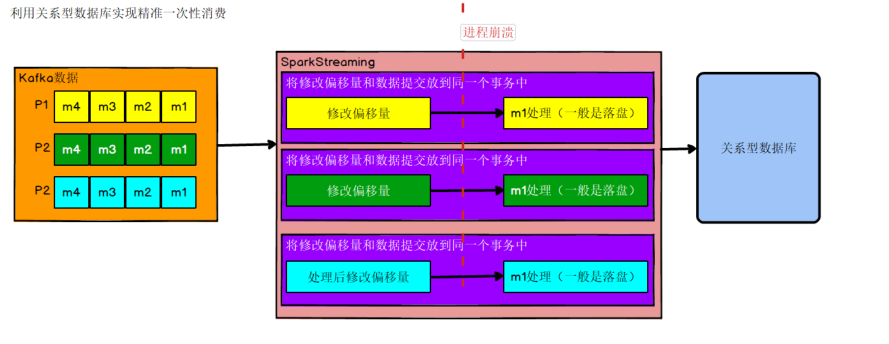
策略二
我们知道如果能够同时解决数据丢失和数据重复问题,就等于做到了精确一次消费。那就各个击破
首先解决数据丢失问题,办法就是要等数据保存成功后再提交偏移量,所以就必须手工来控制偏移量的提交时机。
但是如果数据保存了,没等偏移量提交进程挂了,数据会被重复消费。怎么办?那就要把数据的保存做成幂等性保存。即同一批数据反复保存多次,数据不会翻倍,保存一次和保存一百次的效果是一样的。如果能做到这个,就达到了幂等性保存,就不用担心数据会重复了。
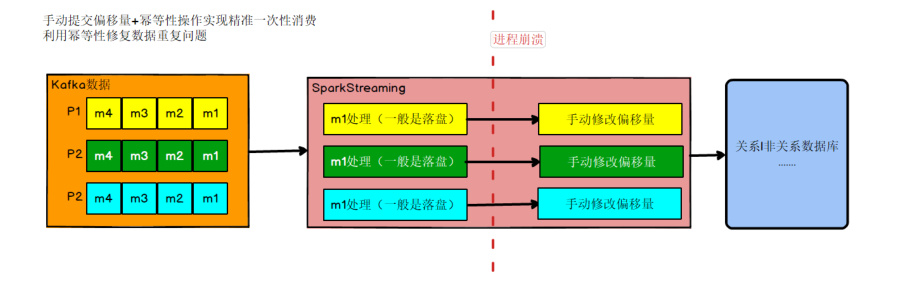
# 手动提交偏移流程
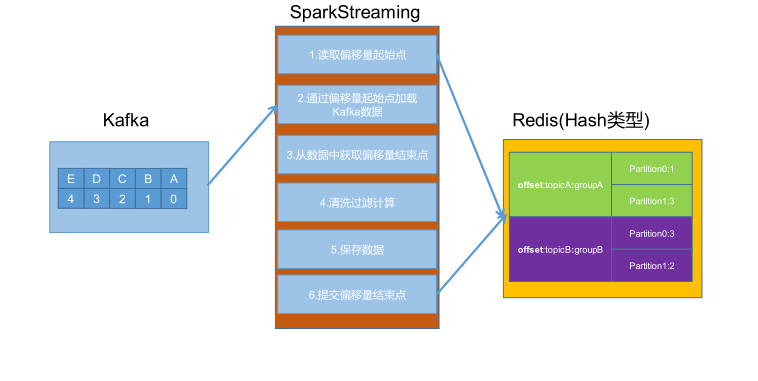
代码实现
package top.damoncai.rtdw.utils
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import redis.clients.jedis.Jedis
import java.util
object OffsetManagerUtil {
/**
* 从 Redis 中读取偏移量
* Reids 格式: type=>Hash [key=>offset:topic:groupId field=>partitionId ·value=> 偏移量值 ] expire 不需要指定
* @param topicName 主题名称
* @param groupId 消费者组
* @return 当前消费者组中,消费的主题对应的分区的偏移量信息
* KafkaUtils.createDirectStream 在读取数据的时候封装了Map[TopicPartition,Long]
*/
def getOffset(topicName:String,groupId:String): Map[TopicPartition,Long] ={
//获取 Redis 客户端
val jedis: Jedis = MyRedisUtil.getJedisClient
//拼接 Reids 中存储偏移量的 key
val offsetKey: String = "offset:" + topicName + ":" + groupId
//根据 key 从 Reids 中获取数据
val offsetMap: util.Map[String, String] = jedis.hgetAll(offsetKey)
//关闭客户端
jedis.close()
//将 Java 的 Map 转换为 Scala 的 Map,方便后续操作
import scala.collection.JavaConverters._
val kafkaOffsetMap: Map[TopicPartition, Long] = offsetMap.asScala.map {
case (partitionId, offset) => {
println("读取分区偏移量:" + partitionId + ":" + offset)
//将 Redis 中保存的分区对应的偏移量进行封装
(new TopicPartition(topicName, partitionId.toInt), offset.toLong)
}
}.toMap
kafkaOffsetMap
}
/**
* 向 Redis 中保存偏移量
* Reids 格式: type=>Hash [key=>offset:topic:groupId field=>partitionId value=>
偏移量值 ] expire 不需要指定
*
* @param topicName 主题名
* @param groupId 消费者组
* @param offsetRanges 当前消费者组中,消费的主题对应的分区的偏移量起始和结束信息
*/
def
saveOffset(topicName:String,groupId:String,offsetRanges:Array[OffsetRange]):
Unit ={
//定义 Java 的 map 集合,用于向 Reids 中保存数据
val offsetMap: util.HashMap[String, String] = new
util.HashMap[String,String]()
//对封装的偏移量数组 offsetRanges 进行遍历
for (offset <- offsetRanges) {
//获取分区
val partition: Int = offset.partition
//获取结束点
val untilOffset: Long = offset.untilOffset
//封装到 Map 集合中
offsetMap.put(partition.toString,untilOffset.toString)
//打印测试
println("保存分区:" + partition +":" + offset.fromOffset+"--->" +
offset.untilOffset)
}
//拼接 Reids 中存储偏移量的 key
val offsetKey: String = "offset:" + topicName + ":" + groupId
//如果需要保存的偏移量不为空 执行保存操作
if(offsetMap!=null&&offsetMap.size()>0){
//获取 Redis 客户端
val jedis: Jedis = MyRedisUtil.getJedisClient
//保存到 Redis 中
jedis.hmset(offsetKey,offsetMap)
//关闭客户端
jedis.close()
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
package top.damoncai.rtdw.app
import com.alibaba.fastjson.{JSON, JSONObject}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
import top.damoncai.rtdw.bean.DauInfo
import top.damoncai.rtdw.utils.{ESUtil, MyKafkaUtil, MyRedisUtil, OffsetManagerUtil}
import java.text.SimpleDateFormat
import java.util.Date
import java.lang
import scala.collection.mutable.ListBuffer
object DauApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("dau_app")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "gmall_dau_bak"
val topic = "gmall_start_0523"
//从 Redis 中读取 Kafka 偏移量
val kafkaOffsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic,groupId)
var recordDstream: InputDStream[ConsumerRecord[String, String]] = null
if(kafkaOffsetMap!=null&&kafkaOffsetMap.size>0){
//Redis 中有偏移量 根据 Redis 中保存的偏移量读取
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc,kafkaOffsetMap,groupId)
}else{
// Redis 中没有保存偏移量 Kafka 默认从最新读取
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc,groupId)
}
// 得到本批次中处理数据的分区对应的偏移量起始及结束位置
// 注意:这里我们从 Kafka 中读取数据之后,直接就获取了偏移量的位置,因为 KafkaRDD 可以转换为 HasOffsetRanges,会自动记录位置
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] = recordDstream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
println(offsetRanges(0).untilOffset + "*****")
rdd
}
}
val jsonObjDStream: DStream[JSONObject] = offsetDStream.map { record =>
//获取启动日志
val jsonStr: String = record.value()
//将启动日志转换为 json 对象
val jsonObj: JSONObject = JSON.parseObject(jsonStr)
//获取时间戳 毫秒数
val ts: lang.Long = jsonObj.getLong("ts")
//获取字符串 日期 小时
val dateHourString: String = new SimpleDateFormat("yyyy-MM-dd HH").format(new Date(ts))
//对字符串日期和小时进行分割,分割后放到 json 对象中,方便后续处理
val dateHour: Array[String] = dateHourString.split(" ")
jsonObj.put("dt",dateHour(0))
jsonObj.put("hr",dateHour(1))
jsonObj
}
jsonObjDStream.print()
// Redis去重 - 方法一 存在缺陷
// val filterJsonObjDStream: DStream[JSONObject] = jsonObjDStream.filter{
// jsonObj => {
// val jedisClient: Jedis = MyRedisUtil.getJedisClient
// //当前日期
// val dt = jsonObj.getString("dt")
// // 设备
// val mid: String = jsonObj.getJSONObject("common").getString("mid")
//
// val key: String = "dau:" + dt
// // 判断Redis中是否存在数据
// val isNew: lang.Long = jedisClient.sadd(key, mid)
// if (isNew == 1L) { // 第一次添加
// jedisClient.expireAt(key,3600*24) // 设置过期时间
// jedisClient.close()
// true
// } else { // 已存在
// jedisClient.close()
// false
// }
// }
// }
//方案 2 以分区为单位进行过滤,可以减少和连接池交互的次数
val filteredDStream: DStream[JSONObject] = jsonObjDStream.mapPartitions {
jsonObjItr => {
//获取 Redis 客户端
val jedisClient: Jedis = MyRedisUtil.getJedisClient()
//定义当前分区过滤后的数据
val filteredList: ListBuffer[JSONObject] = new ListBuffer[JSONObject]
for (jsonObj <- jsonObjItr) {
//获取当前日期
val dt: String = jsonObj.getString("dt")
//获取设备 mid
val mid: String = jsonObj.getJSONObject("common").getString("mid")
//拼接向 Redis 放的数据的 key
val dauKey: String = "dau:" + dt
//判断 Redis 中是否存在该数据
val isNew: lang.Long = jedisClient.sadd(dauKey,mid)
//设置当天的 key 数据失效时间为 24 小时
jedisClient.expire(dauKey,3600*24)
if (isNew == 1L) {
//如果 Redis 中不存在,那么将数据添加到新建的 ListBuffer 集合中,实现过滤的效果
filteredList.append(jsonObj)
}
}
jedisClient.close()
filteredList.toIterator
}
}
//输出测试 数量会越来越少,最后变为 0 因为我们 mid 只是模拟了 50 个
// 向ES中插入数据
filteredDStream.foreachRDD{
rdd=>{//获取 DS 中的 RDD
rdd.foreachPartition{//以分区为单位对 RDD 中的数据进行处理,方便批量插入
jsonItr=>{
val dauList: List[DauInfo] = jsonItr.map {
jsonObj => {
//每次处理的是一个 json 对象 将 json 对象封装为样例类
val commonJsonObj: JSONObject = jsonObj.getJSONObject("common")
DauInfo(
commonJsonObj.getString("mid"),
commonJsonObj.getString("uid"),
commonJsonObj.getString("ar"),
commonJsonObj.getString("ch"),
commonJsonObj.getString("vc"),
jsonObj.getString("dt"),
jsonObj.getString("hr"),
"00", //分钟我们前面没有转换,默认 00
jsonObj.getLong("ts")
)
}
}.toList
//对分区的数据进行批量处理
//获取当前日志字符串
val dt: String = new SimpleDateFormat("yyyy-MM-dd").format(new Date())
ESUtil.bulkInsert(dauList,"gmall2020_dau_info_" + dt)
}
}
//在保存最后提交偏移量
OffsetManagerUtil.saveOffset(topic,groupId,offsetRanges)
}
}
// jsonObjDStream.foreachRDD(jsonObjRDD => {
// })
//测试输出 2
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
# 用户首单
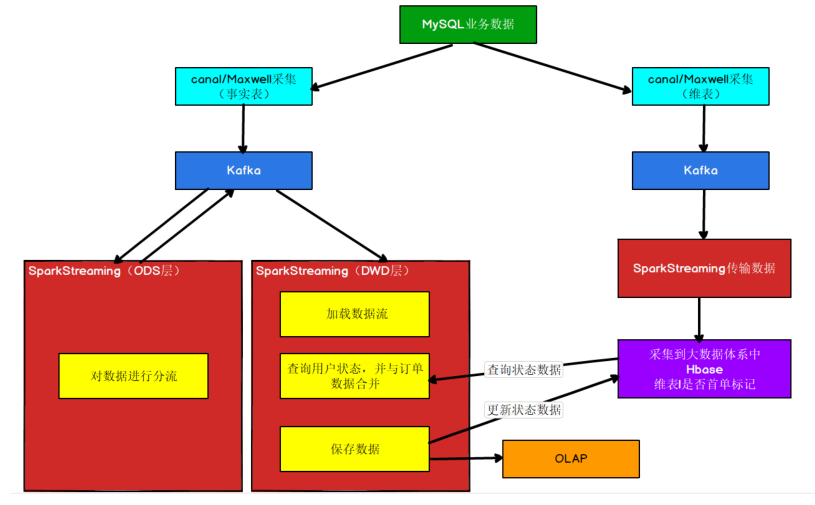
# canal 版本的 ODS 层处理
# 数据格式
{"data":[{"id":"16","user_name":"zhang3","tel":"13810001010"},{"id":"17","user_nam
e":"zhang3","tel":"13810001010"}],"database":"gmall-2020-04","es":158919650200
0,"id":4,"isDdl":false,"mysqlType":{"id":"bigint(20)","user_name":"varchar(20)","tel":"
varchar(20)"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":-5,"user_name":12,"t
el":12},"table":"z_user_info","ts":1589196502433,"type":"INSERT"}
2
3
4
5
# SparkStreaming 对 Topic 分流业务代码
# Kafka 发送数据工具类
object MyKafkaSink {
private val properties: Properties = MyPropertiesUtil.load("config.properties")
val broker_list = properties.getProperty("kafka.broker.list")
var kafkaProducer: KafkaProducer[String, String] = null
def createKafkaProducer:KafkaProducer[String,String] = {
val properties = new Properties
properties.put("bootstrap.servers", broker_list)
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
properties.put("enable.idempotence",(true: java.lang.Boolean))
var producer: KafkaProducer[String, String] = null
try
producer = new KafkaProducer[String, String](properties)
catch {
case e: Exception =>
e.printStackTrace()
}
producer
}
/**
* 发送消息
* @param topic
* @param key
* @param msg
*/
def send(topic: String,key: String,msg: String): Unit = {
if (kafkaProducer == null) kafkaProducer = createKafkaProducer
kafkaProducer.send(new ProducerRecord[String, String](topic, msg))
}
def send(topic: String, msg: String): Unit = {
if (kafkaProducer == null) kafkaProducer = createKafkaProducer
kafkaProducer.send(new ProducerRecord[String, String](topic, msg))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
# 分流逻辑
object BaseDBCanalApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("BaseDBCanalApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "gmall2020_db_c"
val groupId = "base_db_canal_group"
//从 Redis 中读取偏移量
var recoredDStream: InputDStream[ConsumerRecord[String, String]] = null
val kafkaOffsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic,groupId)
if(kafkaOffsetMap!=null && kafkaOffsetMap.size >0){
recoredDStream = MyKafkaUtil.getKafkaStream(topic,ssc,kafkaOffsetMap,groupId)
}else{
recoredDStream = MyKafkaUtil.getKafkaStream(topic,ssc,groupId)
}
//获取当前采集周期中处理的数据 对应的分区已经偏移量
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] =
recoredDStream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//将从 kafka 中读取到的 recore 数据进行封装为 json 对象
val jsonObjDStream: DStream[JSONObject] = offsetDStream.map {
record => {
//获取 value 部分的 json 字符串
val jsonStr: String = record.value()
//将 json 格式字符串转换为 json 对象
val jsonObject: JSONObject = JSON.parseObject(jsonStr)
jsonObject
}
}
//从 json 对象中获取 table 和 data,发送到不同的 kafka 主题
jsonObjDStream.foreachRDD{
rdd=>{
rdd.foreach{
jsonObj=>{
//获取更新的表名
val tableName: String = jsonObj.getString("table")
//获取当前对表数据的更新
val dataArr: JSONArray = jsonObj.getJSONArray("data")
val opType: String = jsonObj.getString("type")
//拼接发送的主题
var sendTopic = "ods_" + tableName
import scala.collection.JavaConverters._
if("INSERT".equals(opType)){
for (data <- dataArr.asScala) {
val msg: String = data.toString
//向 kafka 发送消息
MyKafkaSink.send(sendTopic,msg)
}
}
}
}
//修改 Redis 中 Kafka 的偏移量
OffsetManagerUtil.saveOffset(topic,groupId,offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# Maxwell 版本的 ODS 层处理
执行 insert 测试语句
INSERT INTO z_user_info VALUES(30,'zhang3','13810001010'),(31,'li4','1389999999');

执行 update 操作
UPDATE z_user_info SET user_name='wang55' WHERE id IN(30,31)

delete 操作
DELETE FROM z_user_info WHERE id IN(30,31)

# 总结数据特点
日志结构
canal 每一条 SQL 会产生一条日志,如果该条 Sql 影响了多行数据,则已经会通过集合的方式归集在这条日志中。(即使是一条数据也会是数组结构)
maxwell 以影响的数据为单位产生日志,即每影响一条数据就会产生一条日志。如果想知道这些日志是否是通过某一条 sql 产生的可以通过 xid 进行判断,相同的 xid 的日志来自同一 sql。
数字类型
当原始数据是数字类型时,maxwell 会尊重原始数据的类型不增加双引,变为字符串。canal 一律转换为字符串。
带原始数据字段定义
canal 数据中会带入表结构。maxwell 更简洁。
# SparkStreaming 对 Topic 分流业务代码
object BaseDBMaxwellApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("BaseDBCanalApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "gmall2020_db_m"
val groupId = "base_db_maxwell_group"
//从 Redis 中读取偏移量
var recoredDStream: InputDStream[ConsumerRecord[String, String]] = null
val kafkaOffsetMap: Map[TopicPartition, Long] =
OffsetManagerUtil.getOffset(topic,groupId)
if(kafkaOffsetMap!=null && kafkaOffsetMap.size >0){
recoredDStream =
MyKafkaUtil.getKafkaStream(topic,ssc,kafkaOffsetMap,groupId)
}else{
recoredDStream = MyKafkaUtil.getKafkaStream(topic,ssc,groupId)
}
//获取当前采集周期中处理的数据 对应的分区已经偏移量
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] =
recoredDStream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//将从 kafka 中读取到的 recore 数据进行封装为 json 对象
val jsonObjDStream: DStream[JSONObject] = offsetDStream.map {
record => {
//获取 value 部分的 json 字符串
val jsonStr: String = record.value()
//将 json 格式字符串转换为 json 对象
val jsonObject: JSONObject = JSON.parseObject(jsonStr)
jsonObject
}
}
//从 json 对象中获取 table 和 data,发送到不同的 kafka 主题
jsonObjDStream.foreachRDD{
rdd=>{
rdd.foreach{
jsonObj=>{
val opType: String = jsonObj.getString("type")
val dataJsonObj: JSONObject = jsonObj.getJSONObject("data")
if(dataJsonObj!=null && !dataJsonObj.isEmpty
&& !"delete".equals(opType)){
//获取更新的表名
val tableName: String = jsonObj.getString("table")
//拼接发送的主题
var sendTopic = "ods_" + tableName
//向 kafka 发送消息
MyKafkaSink.send(sendTopic,dataJsonObj.toString())
}
}
}
//修改 Redis 中 Kafka 的偏移量
OffsetManagerUtil.saveOffset(topic,groupId,offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# phoenix
# 安装
解压 squirrel-sql-3.9.1.zip
将phoenix-5.0.0-HBase-2.0-server.jar包放到集群各个节点lib目录下
在解压后的目录双击运行 squirrel-sql.bat
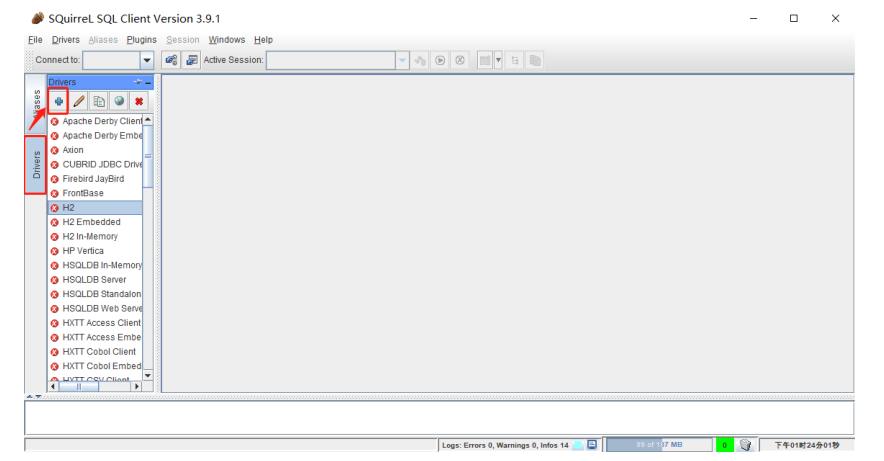
添加 phoenix 驱动
具体驱动配置如下
Example URL jdbc:phoenix:ha01,ha02,ha03:2181 Class Name org.apache.phoenix.jdbc.PhoenixDriver1
2
3
4
5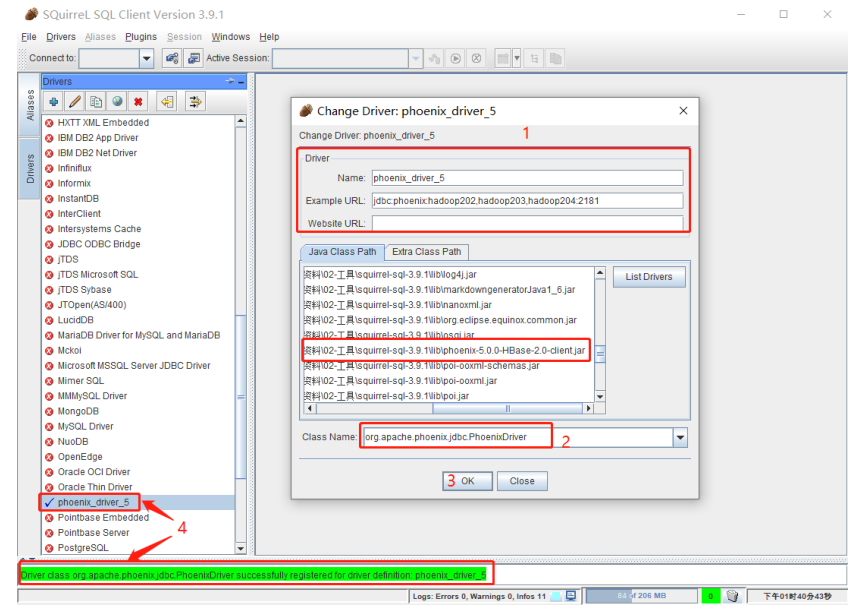
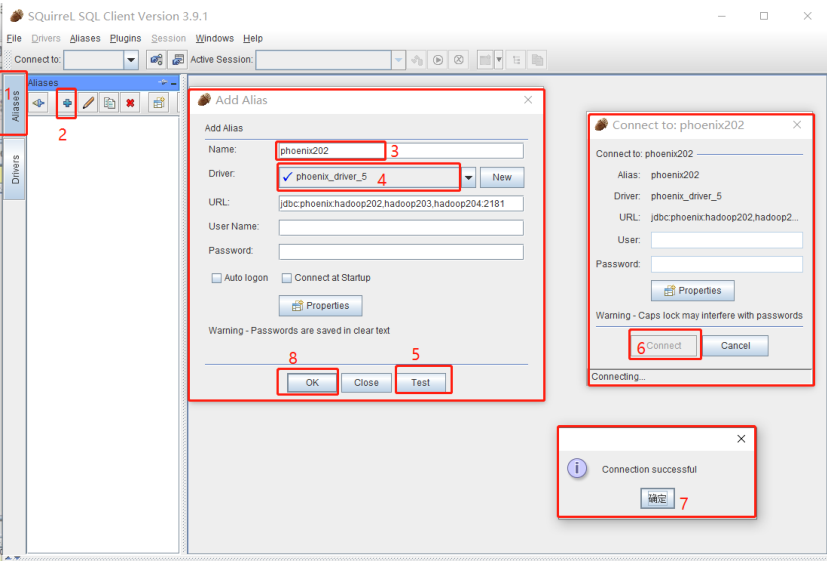
创建连接
提前启动好 hdfs 以及 hbase
# 代码实现
在 pom.xml 文件中加入相关依赖
<dependency> <groupId>org.apache.phoenix</groupId> <artifactId>phoenix-spark</artifactId> <version>5.0.0-HBase-2.0</version> <exclusions> <exclusion> <groupId>org.glassfish</groupId> <artifactId>javax.el</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.glassfish</groupId> <artifactId>javax.el</artifactId> <version>3.0.1-b06</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>${spark.version}</version> </dependency>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21创建 OrderInfo 样例类
case class OrderInfo ( id: Long, //订单编号 province_id: Long, //省份 id order_status: String, //订单状态 user_id: Long, //用户 id final_total_amount: Double, //总金额 benefit_reduce_amount: Double, //优惠金额 original_total_amount: Double, //原价金额 feight_fee: Double, //运费 expire_time: String, //失效时间 create_time: String, //创建时间 operate_time: String, //操作时间 var create_date: String, //创建日期 var create_hour: String, //创建小时 var if_first_order:String, //是否首单 var province_name:String, //地区名 var province_area_code:String, //地区编码 var province_iso_code:String, //国际地区编码 var user_age_group:String, //用户年龄段 var user_gender:String //用户性别 )1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21创建 UserStatus 样例类
class UserStatus ( userId:String, //用户 id ifConsumed:String //是否消费过 0 首单 1 非首单 )1
2
3
4创建 phoenix 查询工具类 PhoenixUtil
object PhoenixUtil { def main(args: Array[String]): Unit = { val list: List[ JSONObject] = queryList("select * from user_status2020") println(list) } def queryList(sql:String):List[JSONObject]={ Class.forName("org.apache.phoenix.jdbc.PhoenixDriver") val resultList: ListBuffer[JSONObject] = new ListBuffer[ JSONObject]() val conn: Connection = DriverManager.getConnection("jdbc:phoenix:ha01,ha02,ha03:2181") val stat: Statement = conn.createStatement println(sql) val rs: ResultSet = stat.executeQuery(sql ) val md: ResultSetMetaData = rs.getMetaData while ( rs.next ) { val rowData = new JSONObject(); for (i <-1 to md.getColumnCount ) { rowData.put(md.getColumnName(i), rs.getObject(i)) } resultList+=rowData } stat.close() conn.close() resultList.toList } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26读取订单信息,查询用户状态(判断是否首单)
package top.damoncai.rtdw.dwd import com.alibaba.fastjson.{JSON, JSONObject} import org.apache.hadoop.conf.Configuration import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange} import org.apache.spark.streaming.{Seconds, StreamingContext} import top.damoncai.rtdw.bean.{OrderInfo, UserStatus} import top.damoncai.rtdw.utils.{MyKafkaUtil, OffsetManagerUtil, PhoenixUtil} object OrderInfoApp { def main(args: Array[String]): Unit = { //1.从 Kafka 中查询订单信息 val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("OrderInfoApp") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topic = "ods_order_info" val groupId = "order_info_group" //从 Redis 中读取 Kafka 偏移量 val kafkaOffsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId) var recordDstream: InputDStream[ConsumerRecord[String, String]] = null if (kafkaOffsetMap != null && kafkaOffsetMap.size > 0) { //Redis 中有偏移量 根据 Redis 中保存的偏移量读取 recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, kafkaOffsetMap, groupId) } else { // Redis 中没有保存偏移量 Kafka 默认从最新读取 recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId) } //得到本批次中处理数据的分区对应的偏移量起始及结束位置 // 注意:这里我们从 Kafka 中读取数据之后,直接就获取了偏移量的位置,因为 KafkaRDD 可以转 换为 HasOffsetRanges,会自动记录位置 var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange] val offsetDStream: DStream[ConsumerRecord[String, String]] = recordDstream.transform { rdd => { offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd } } //对从 Kafka 中读取到的数据进行结构转换,由 Kafka 的 ConsumerRecord 转换为一个 OrderInfo 对象 val orderInfoDStream: DStream[OrderInfo] = offsetDStream.map { record => { val jsonString: String = record.value() val orderInfo: OrderInfo = JSON.parseObject(jsonString,classOf[OrderInfo]) //通过对创建时间 2020-07-13 01:38:16 进行拆分,赋值给日期和小时属性,方便后续 处理 val createTimeArr: Array[String] = orderInfo.create_time.split(" ") //获取日期赋给日期属性 orderInfo.create_date = createTimeArr(0) //获取小时赋给小时属性 orderInfo.create_hour = createTimeArr(1).split(":")(0) orderInfo } } //方案 1:对 DStream 中的数据进行处理,判断下单的用户是否为首单 //缺点:每条订单数据都要执行一次 SQL,SQL 执行过于频繁 // val orderInfoWithFirstFlagDStream: DStream[OrderInfo] = // orderInfoDStream.map { // orderInfo => { // //通过 phoenix 工具到 hbase 中查询用户状态 // var sql: String = s"select user_id,if_consumed from user_status2020 where user_id ='${orderInfo.user_id}'" // val userStatusList: List[JSONObject] = PhoenixUtil.queryList(sql) // if (userStatusList != null && userStatusList.size > 0) { // orderInfo.if_first_order = "0" // } else { // orderInfo.if_first_order = "1" // } // orderInfo // } // } // orderInfoWithFirstFlagDStream.print(1000) //方案 2:对 DStream 中的数据进行处理,判断下单的用户是否为首单 //优化:以分区为单位,将一个分区的查询操作改为一条 SQL val orderInfoWithFirstFlagDStream: DStream[OrderInfo] = orderInfoDStream.mapPartitions { orderInfoItr => { //因为迭代器迭代之后就获取不到数据了,所以将迭代器转换为集合进行操作 val orderInfoList: List[OrderInfo] = orderInfoItr.toList //获取当前分区内的用户 ids val userIdList: List[Long] = orderInfoList.map(_.user_id) //从 hbase 中查询整个分区的用户是否消费过,获取消费过的用户 ids var sql: String = s"select user_id,if_consumed from user_status2020 whereuser_id in('${userIdList.mkString("','")}')" val userStatusList: List[JSONObject] = PhoenixUtil.queryList(sql) //得到已消费过的用户的 id 集合 val cosumedUserIdList: List[String] = userStatusList.map(_.getString("USER_ID")) //对分区数据进行遍历 for (orderInfo <- orderInfoList) { // 注意:orderInfo 中 中 user_id 是 是 Long 类型,一定别忘了进行转换 if (cosumedUserIdList.contains(orderInfo.user_id.toString)) { //如已消费过的用户的 id 集合包含当前下订单的用户,说明不是首单 orderInfo.if_first_order = "0" } else { orderInfo.if_first_order = "1" } } orderInfoList.toIterator } } //===============4.同批次状态修正================= //因为要使用 groupByKey 对用户进行分组,所以先对 DStream 中的数据结构进行转换 val orderInfoWithKeyDStream: DStream[(Long, OrderInfo)] = orderInfoWithFirstFlagDStream.map { orderInfo => { (orderInfo.user_id, orderInfo) } } //按照用户 id 对当前采集周期数据进行分组 val groupByKeyDStream: DStream[(Long, Iterable[OrderInfo])] = orderInfoWithKeyDStream.groupByKey() //对分组后的用户订单进行判断 val orderInfoRealWithFirstFlagDStream: DStream[OrderInfo] = groupByKeyDStream.flatMap { case (userId, orderInfoItr) => { //如果同一批次有用户的订单数量大于 1 了 if (orderInfoItr.size > 1) { //对用户订单按照时间进行排序 val sortedList: List[OrderInfo] = orderInfoItr.toList.sortWith( (orderInfo1, orderInfo2) => { orderInfo1.create_time < orderInfo2.create_time } ) //获取排序后集合的第一个元素 val orderInfoFirst: OrderInfo = sortedList(0) //判断是否为首单 if (orderInfoFirst.if_first_order == "1") { //将除了首单的其它订单设置为非首单 for (i <- 1 to sortedList.size - 1) { val orderInfoNotFirst: OrderInfo = sortedList(i) orderInfoNotFirst.if_first_order = "0" } } sortedList } else { orderInfoItr.toList } } } //导入类下成员 import org.apache.phoenix.spark._ orderInfoWithFirstFlagDStream.foreachRDD{ rdd=>{ //从所有订单中,将首单的订单过滤出来 val firstOrderRDD: RDD[OrderInfo] = rdd.filter(_.if_first_order=="1") //获取当前订单用户并更新到 Hbase,注意:saveToPhoenix 在更新的时候,要求 rdd 中的属性 和插入 hbase 表中的列数必须保持一致,所以转换一下 val firstOrderUserRDD: RDD[UserStatus] = firstOrderRDD.map { orderInfo => UserStatus(orderInfo.user_id.toString, "1") } firstOrderUserRDD.saveToPhoenix( "USER_STATUS2020", Seq("USER_ID","IF_CONSUMED"), new Configuration, Some("ha01,ha02,ha03:2181") ) //保存偏移量到 Redis OffsetManagerUtil.saveOffset(topic,groupId,offsetRanges) } orderInfoWithFirstFlagDStream.print() ssc.start() ssc.awaitTermination() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
# 订单与维度表的关联
# 维度表的读取
# 通过 phoenix 在 Hbase 中建表
创建省份表
create table gmall2020_province_info (id varchar primary key,info.name varchar,info.area_code varchar,info.iso_code varchar)SALT_BUCKETS = 31创建用户表
create table gmall2020_user_info (id varchar primary key ,user_level varchar, birthday varchar,gender varchar, age_group varchar , gender_name varchar)SALT_BUCKETS = 31
# 创建样例类ProviceInfo
case class ProviceInfo(
id:String,
name:String,
area_code:String,
iso_code:String,
)
2
3
4
5
6
# 用户样例类UserInfo
case class UserInfo(
id:String,
user_level:String,
birthday:String,
gender:String,
var age_group:String, //年龄段
var gender_name:String //性别
)
2
3
4
5
6
7
8
# 创建 SparkStreaming 读取省份维度数据
# 读取省份维度数据类 ProvinceInfoApp
object ProvinceInfoApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setMaster("provinceInfoApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_base_province"
val groupId = "province_info_group"
// 1.从Redis中获取Kafka偏移量
val kafkaOffsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId)
var recordDstream: InputDStream[ConsumerRecord[String, String]] = null;
// Redis中偏移量
if(kafkaOffsetMap != null && kafkaOffsetMap.size > 0) {
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, kafkaOffsetMap, groupId);
}else{
// Redis 中没有保存偏移量 Kafka 默认从最新读取
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc,groupId)
}
//得到本批次中处理数据的分区对应的偏移量起始及结束位置
// 注意:这里我们从 Kafka 中读取数据之后,直接就获取了偏移量的位置,因为 KafkaRDD 可以转 换为 HasOffsetRanges,会自动记录位置
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] = recordDstream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//写入到 Hbase 中
//写入到 Hbase 中
offsetDStream.foreachRDD{
rdd=>{
val provinceInfoRDD: RDD[ProvinceInfo] = rdd.map {
record => {
//得到从 kafka 中读取的 jsonString
val jsonString: String = record.value()
//转换为 ProvinceInfo
val provinceInfo: ProvinceInfo = JSON.parseObject(jsonString,
classOf[ProvinceInfo])
provinceInfo
}
}
//保存到 hbase
import org.apache.phoenix.spark._
provinceInfoRDD.saveToPhoenix(
"gmall2020_province_info",
Seq("ID","NAME","AREA_CODE","ISO_CODE"),
new Configuration,
Some("ha01,ha02,ha03:2181")
)
//提交偏移量
OffsetManagerUtil.saveOffset(topic,groupId,offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# 读取用户维度数据类 UserInfoApp
object UserInfoApp {
object UserInfoApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("UserInfoApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_user_info";
val groupId = "gmall_user_info_group"
val offset: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic,
groupId)
var inputDstream: InputDStream[ConsumerRecord[String, String]] = null
// 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用 kafka 读出默认最新的数据
if (offset != null && offset.size > 0) {
inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offset, groupId)
} else {
inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
}
//取得偏移量步长
var offsetRanges: Array[OffsetRange] = null
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
inputDstream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
val userInfoDstream: DStream[UserInfo] = inputGetOffsetDstream.map {
record => {
val userInfoJsonStr: String = record.value()
val userInfo: UserInfo = JSON.parseObject(userInfoJsonStr,
classOf[UserInfo])
//把生日转成年龄
val formattor = new SimpleDateFormat("yyyy-MM-dd")
val date: util.Date = formattor.parse(userInfo.birthday)
val curTs: Long = System.currentTimeMillis()
val betweenMs = curTs - date.getTime
val age = betweenMs / 1000L / 60L / 60L / 24L / 365L
if (age < 20) {
userInfo.age_group = "20 岁及以下"
} else if (age > 30) {
userInfo.age_group = "30 岁以上"
} else {
userInfo.age_group = "21 岁到 30 岁"
}
if (userInfo.gender == "M") {
userInfo.gender_name = "男"
} else {
userInfo.gender_name = "女"
}
userInfo
}
}
userInfoDstream.foreachRDD {
rdd => {
import org.apache.phoenix.spark._
rdd.saveToPhoenix(
"GMALL2020_USER_INFO",
Seq("ID", "USER_LEVEL", "BIRTHDAY", "GENDER", "AGE_GROUP", "GENDER_NAME")
, new Configuration, Some("ha01,ha02,ha03:2181")
)
OffsetManagerUtil.saveOffset(groupId, topic, offsetRanges)
}
}
ssc.start()
ssc.awaitTermination()
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 利用 maxwell-bootstrap 初始化数据
初始化省份表
bin/maxwell-bootstrap --user maxwell --password maxwell --host ha01 --database gmall2020 --table base_province --client_id maxwell_1
初始化用户表
bin/maxwell-bootstrap --user maxwell --password maxwell --host ha01 --database gmall2020 --table user_info --client_id maxwell_1
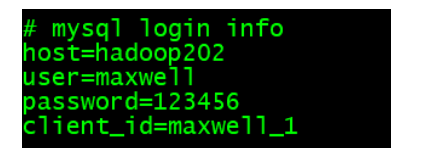
maxwell-bootstrap不具备将数据直接导入kafka或者hbase的能力,通过--client_id指定将数据交给哪个 maxwell 进程处理,在 maxwell 的 conf.properties 中配置
# 测试
运行 BaseDBMaxwellApp、ProvinceInfoApp、UserInfoApp 同步数据
在 maxwell 执行 bin/maxwell-bootstrap 脚本
注意:BaseDBMaxwellApp 会出现异常
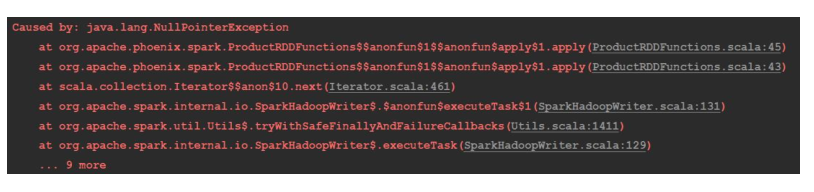
是因为使用 bin/maxwell-bootstrap 同步原始数据的时候,会生成两条标记起始和结束的 json 字符串,这两条数据的 data 属性是 null 的,并且 type 属性也和原来的标记不一样,例如:插入操作标记位 bootstrap-insert
解决:修改 BaseDBMaxwellApp 分流的代码
object BaseDBMaxwellApp { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("BaseDBCanalApp") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topic = "gmall2020_db_m" val groupId = "base_db_maxwell_group" //从 Redis 中读取偏移量 var recoredDStream: InputDStream[ConsumerRecord[String, String]] = null val kafkaOffsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic,groupId) if(kafkaOffsetMap!=null && kafkaOffsetMap.size >0){ recoredDStream = MyKafkaUtil.getKafkaStream(topic,ssc,kafkaOffsetMap,groupId) }else{ recoredDStream = MyKafkaUtil.getKafkaStream(topic,ssc,groupId) } //获取当前采集周期中处理的数据 对应的分区已经偏移量 var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange] val offsetDStream: DStream[ConsumerRecord[String, String]] = recoredDStream.transform { rdd => { offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd } } //将从 kafka 中读取到的 recore 数据进行封装为 json 对象 val jsonObjDStream: DStream[JSONObject] = offsetDStream.map { record => { //获取 value 部分的 json 字符串 val jsonStr: String = record.value() //将 json 格式字符串转换为 json 对象 val jsonObject: JSONObject = JSON.parseObject(jsonStr) jsonObject } } //从 json 对象中获取 table 和 data,发送到不同的 kafka 主题 jsonObjDStream.foreachRDD { rdd => { rdd.foreach { jsonObj => { val opType: String = jsonObj.getString("type") val tableName: String = jsonObj.getString("table") val dataObj: JSONObject = jsonObj.getJSONObject("data") if (dataObj != null && !dataObj.isEmpty) { if ( ("order_info".equals(tableName) && "insert".equals(opType)) || (tableName.equals("order_detail") && "insert".equals(opType)) || tableName.equals("base_province") || tableName.equals("user_info") || tableName.equals("sku_info") || tableName.equals("base_trademark") || tableName.equals("base_category3") || tableName.equals("spu_info") ) { //获取更新的表名 val tableName: String = jsonObj.getString("table") //拼接发送的主题 var sendTopic = "ods_" + tableName //向 kafka 发送消息 MyKafkaSink.send(sendTopic, dataObj.toString()) } } } //修改 Redis 中 Kafka 的偏移量 OffsetManagerUtil.saveOffset(topic, groupId, offsetRanges) } } } ssc.start() ssc.awaitTermination() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
# 订单表和维度表的关联
# OrderInfoApp 代码
object OrderInfoApp {
def main(args: Array[String]): Unit = {
//1.从 Kafka 中查询订单信息
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("OrderInfoApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_order_info"
val groupId = "order_info_group"
//从 Redis 中读取 Kafka 偏移量
val kafkaOffsetMap: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId)
var recordDstream: InputDStream[ConsumerRecord[String, String]] = null
if (kafkaOffsetMap != null && kafkaOffsetMap.size > 0) {
//Redis 中有偏移量 根据 Redis 中保存的偏移量读取
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, kafkaOffsetMap, groupId)
} else {
// Redis 中没有保存偏移量 Kafka 默认从最新读取
recordDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
}
//得到本批次中处理数据的分区对应的偏移量起始及结束位置
// 注意:这里我们从 Kafka 中读取数据之后,直接就获取了偏移量的位置,因为 KafkaRDD 可以转 换为 HasOffsetRanges,会自动记录位置
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val offsetDStream: DStream[ConsumerRecord[String, String]] =
recordDstream.transform {
rdd => {
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//对从 Kafka 中读取到的数据进行结构转换,由 Kafka 的 ConsumerRecord 转换为一个 OrderInfo 对象
val orderInfoDStream: DStream[OrderInfo] = offsetDStream.map {
record => {
val jsonString: String = record.value()
val orderInfo: OrderInfo =
JSON.parseObject(jsonString,classOf[OrderInfo])
//通过对创建时间 2020-07-13 01:38:16 进行拆分,赋值给日期和小时属性,方便后续 处理
val createTimeArr: Array[String] = orderInfo.create_time.split(" ")
//获取日期赋给日期属性
orderInfo.create_date = createTimeArr(0)
//获取小时赋给小时属性
orderInfo.create_hour = createTimeArr(1).split(":")(0)
orderInfo
}
}
//方案 1:对 DStream 中的数据进行处理,判断下单的用户是否为首单
//缺点:每条订单数据都要执行一次 SQL,SQL 执行过于频繁
// val orderInfoWithFirstFlagDStream: DStream[OrderInfo] =
// orderInfoDStream.map {
// orderInfo => {
// //通过 phoenix 工具到 hbase 中查询用户状态
// var sql: String = s"select user_id,if_consumed from user_status2020 where user_id ='${orderInfo.user_id}'"
// val userStatusList: List[JSONObject] = PhoenixUtil.queryList(sql)
// if (userStatusList != null && userStatusList.size > 0) {
// orderInfo.if_first_order = "0"
// } else {
// orderInfo.if_first_order = "1"
// }
// orderInfo
// }
// }
// orderInfoWithFirstFlagDStream.print(1000)
//方案 2:对 DStream 中的数据进行处理,判断下单的用户是否为首单
//优化:以分区为单位,将一个分区的查询操作改为一条 SQL
val orderInfoWithFirstFlagDStream: DStream[OrderInfo] =
orderInfoDStream.mapPartitions {
orderInfoItr => {
//因为迭代器迭代之后就获取不到数据了,所以将迭代器转换为集合进行操作
val orderInfoList: List[OrderInfo] = orderInfoItr.toList
//获取当前分区内的用户 ids
val userIdList: List[Long] = orderInfoList.map(_.user_id)
//从 hbase 中查询整个分区的用户是否消费过,获取消费过的用户 ids
var sql: String = s"select user_id,if_consumed from user_status2020 where user_id in('${userIdList.mkString("','")}')"
val userStatusList: List[JSONObject] = PhoenixUtil.queryList(sql)
//得到已消费过的用户的 id 集合
val cosumedUserIdList: List[String] = userStatusList.map(_.getString("USER_ID"))
//对分区数据进行遍历
for (orderInfo <- orderInfoList) {
// 注意:orderInfo 中 中 user_id 是 是 Long 类型,一定别忘了进行转换
if (cosumedUserIdList.contains(orderInfo.user_id.toString)) {
//如已消费过的用户的 id 集合包含当前下订单的用户,说明不是首单
orderInfo.if_first_order = "0"
} else {
orderInfo.if_first_order = "1"
}
}
orderInfoList.toIterator
}
}
//===============4.同批次状态修正=================
//因为要使用 groupByKey 对用户进行分组,所以先对 DStream 中的数据结构进行转换
val orderInfoWithKeyDStream: DStream[(Long, OrderInfo)] =
orderInfoWithFirstFlagDStream.map {
orderInfo => {
(orderInfo.user_id, orderInfo)
}
}
//按照用户 id 对当前采集周期数据进行分组
val groupByKeyDStream: DStream[(Long, Iterable[OrderInfo])] =
orderInfoWithKeyDStream.groupByKey()
//对分组后的用户订单进行判断
val orderInfoRealWithFirstFlagDStream: DStream[OrderInfo] =
groupByKeyDStream.flatMap {
case (userId, orderInfoItr) => {
//如果同一批次有用户的订单数量大于 1 了
if (orderInfoItr.size > 1) {
//对用户订单按照时间进行排序
val sortedList: List[OrderInfo] = orderInfoItr.toList.sortWith(
(orderInfo1, orderInfo2) => {
orderInfo1.create_time < orderInfo2.create_time
}
)
//获取排序后集合的第一个元素
val orderInfoFirst: OrderInfo = sortedList(0)
//判断是否为首单
if (orderInfoFirst.if_first_order == "1") {
//将除了首单的其它订单设置为非首单
for (i <- 1 to sortedList.size - 1) {
val orderInfoNotFirst: OrderInfo = sortedList(i)
orderInfoNotFirst.if_first_order = "0"
}
}
sortedList
} else {
orderInfoItr.toList
}
}
}
//5.订单与 Hbase 中的维度表进行关联
// orderInfoRealWithFirstFlagDStream.mapPartitions{
// orderInfoItr => {
// val orderInfoList: List[OrderInfo] = orderInfoItr.toList
// //获取本批次中所有订单省份的 ID
// val provinceIdList: List[Long] = orderInfoList.map(_.province_id)
// //根据省份 id 到 Hbase 省份表中获取省份信息
// var sql: String = s"select id,name,area_code,iso_code from gmall0713_province_info where id in('${provinceIdList.mkString("','")}')"
// //{"id":"1","name":"zs","area_code":"1000","iso_code":"CN-JX"}
// val provinceJsonList: List[JSONObject] = PhoenixUtil.queryList(sql)
// //将 provinceInfoList 转换为 Map 集合 [id->{"id":"1","name":"zs","area_code":"1000","iso_code":"CN-JX"}]
// val provinceJsonMap: Map[Long, JSONObject] = provinceJsonList.map {
// proJsonObj => {
// (proJsonObj.getLongValue("ID"), proJsonObj)
// }
// }.toMap
//
// for(orderInfo <- orderInfoList) {
// val province_id: Long = orderInfo.province_id
// val provinceObj: JSONObject = provinceJsonMap.getOrElse(province_id, null)
// if (provinceObj != null) {
// orderInfo.province_iso_code = provinceObj.getString("ISO_CODE")
// orderInfo.province_name = provinceObj.getString("NAME")
// orderInfo.province_area_code = provinceObj.getString("AREA_CODE")
// }
// }
// orderInfoList.toIterator
// }
// }
//5.1 关联省份方案 2 使用广播变量,在 Driver 端进行一次查询 分区越多效果越明显 前提: 省份数据量较小
val orderInfoWithProvinceDStream: DStream[OrderInfo] =
orderInfoRealWithFirstFlagDStream.transform {
rdd => {
//每一个采集周期,都会在 Driver 端 执行从 hbase 中查询身份信息
var sql: String = "select id,name,area_code,iso_code from gmall0713_province_info"
val provinceInfoList: List[JSONObject] = PhoenixUtil.queryList(sql)
//封装广播变量
val provinceInfoMap: Map[String, ProvinceInfo] = provinceInfoList.map {
jsonObj => {
val provinceInfo = ProvinceInfo(
jsonObj.getString("ID"),
jsonObj.getString("NAME"),
jsonObj.getString("AREA_CODE"),
jsonObj.getString("ISO_CODE")
)
(provinceInfo.id, provinceInfo)
}
}.toMap
val provinceInfoBC: Broadcast[Map[String, ProvinceInfo]] =
ssc.sparkContext.broadcast(provinceInfoMap)
val orderInfoWithProvinceRDD: RDD[OrderInfo] = rdd.map {
orderInfo => {
val provinceBCMap: Map[String, ProvinceInfo] = provinceInfoBC.value
val provinceInfo: ProvinceInfo =
provinceBCMap.getOrElse(orderInfo.province_id.toString, null)
if (provinceInfo != null) {
orderInfo.province_name = provinceInfo.name
orderInfo.province_area_code = provinceInfo.area_code
orderInfo.province_iso_code = provinceInfo.iso_code
}
orderInfo
}
}
orderInfoWithProvinceRDD
}
}
//5.2 关联用户
val orderInfoWithUserDStream: DStream[OrderInfo] =
orderInfoWithProvinceDStream.mapPartitions {
orderInfoItr => {
val orderInfoList: List[OrderInfo] = orderInfoItr.toList
val userIdList: List[Long] = orderInfoList.map(_.user_id)
//根据用户 id 到 Phoenix 中查询用户
var sql: String =
s"select id,user_level,birthday,gender,age_group,gender_name from gmall0713_user_info where id in('${userIdList.mkString("','")}')"
val userJsonList: List[JSONObject] = PhoenixUtil.queryList(sql)
val userJsonMap: Map[Long, JSONObject] = userJsonList.map(userJsonObj =>
(userJsonObj.getLongValue("ID"), userJsonObj)).toMap
for (orderInfo <- orderInfoList) {
val userJsonObj: JSONObject = userJsonMap.getOrElse(orderInfo.user_id,
null)
if (userJsonObj != null) {
orderInfo.user_gender = userJsonObj.getString("GENDER_NAME")
orderInfo.user_age_group = userJsonObj.getString("AGE_GROUP")
}
}
orderInfoList.toIterator
}
}
orderInfoWithUserDStream.print(1000)
//导入类下成员
import org.apache.phoenix.spark._
orderInfoWithFirstFlagDStream.foreachRDD {
rdd => {
//从所有订单中,将首单的订单过滤出来
val firstOrderRDD: RDD[OrderInfo] = rdd.filter(_.if_first_order == "1")
//获取当前订单用户并更新到 Hbase,注意:saveToPhoenix 在更新的时候,要求 rdd 中的属性 和插入 hbase 表中的列数必须保持一致,所以转换一下
val firstOrderUserRDD: RDD[UserStatus] = firstOrderRDD.map {
orderInfo => UserStatus(orderInfo.user_id.toString, "1")
}
firstOrderUserRDD.saveToPhoenix(
"USER_STATUS2020",
Seq("USER_ID", "IF_CONSUMED"),
new Configuration,
Some("ha01,ha02,ha03:2181")
)
//保存偏移量到 Redis
OffsetManagerUtil.saveOffset(topic, groupId, offsetRanges)
}
}
orderInfoWithFirstFlagDStream.print()
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
# 订单明细实付金额分摊
# 业务流程图
所以除了订单事实表与维表进行合并形成宽表,还需要订单事实表与订单明细事实表进行合并形成更大的宽表。
# 创建订单明细样例类 OrderDetail
case class OrderDetail(
id: Long,
order_id:Long,
sku_id: Long,
order_price: Double,
sku_num:Long,
sku_name: String,
create_time: String,
var spu_id: Long, //作为维度数据 要关联进来
var tm_id: Long,
var category3_id: Long,
var spu_name: String,
var tm_name: String,
var category3_name: String
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 创建读取订单明细数据的类 OrderDetailApp
object OrderDetailApp {
def main(args: Array[String]): Unit = {
// 加载流 //手动偏移量
val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("OrderDetailApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topic = "ods_order_detail";
val groupId = "order_detail_group"
//从 redis 中读取偏移量
val offsetMapForKafka: Map[TopicPartition, Long] =
OffsetManagerUtil.getOffset(topic, groupId)
//通过偏移量到 Kafka 中获取数据
var recordInputDstream: InputDStream[ConsumerRecord[String, String]] = null
if (offsetMapForKafka != null && offsetMapForKafka.size > 0) {
recordInputDstream = MyKafkaUtil.getKafkaStream(topic, ssc,
offsetMapForKafka, groupId)
} else {
recordInputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
}
//从流中获得本批次的 偏移量结束点(每批次执行一次)
var offsetRanges: Array[OffsetRange] = null //周期性储存了当前批次偏移量的变化状态,重要的是偏移量结束点
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
recordInputDstream.transform {
rdd => {
//周期性在 driver 中执行
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//提取数据
val orderDetailDstream: DStream[OrderDetail] = inputGetOffsetDstream.map {
record =>{
val jsonString: String = record.value()
//订单处理 转换成更方便操作的专用样例类
val orderDetail: OrderDetail = JSON.parseObject(jsonString, classOf[OrderDetail])
orderDetail
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 测试
# 在 Hbase 中创建表与维表对应
创建品牌表
create table gmall2020_base_trademark (id varchar primary key ,tm_name varchar);1创建分类表
create table gmall2020_base_category3 (id varchar primary key ,name varchar ,category2_id varchar);1创建 SPU 表
create table gmall2020_spu_info (id varchar primary key ,spu_name varchar);1创建商品表
create table gmall2020_sku_info (id varchar primary key , spu_id varchar, price varchar, sku_name varchar, tm_id varchar,category3_id varchar, create_time varchar,category3_name varchar, spu_name varchar, tm_name varchar ) SALT_BUCKETS = 3;1
# 创建对应的样例类
品牌样例类
case class BaseTrademark( tm_id:String , tm_name:String )1
2
3
4分类样例类
case class BaseCategory3( id:String , name:String , category2_id:String )1
2
3
4
5
6Spu 样例类
case class SpuInfo( id:String , spu_name:String )1
2
3
4商品样例类
case class SkuInfo(id:String , spu_id:String , price:String , sku_name:String , tm_id:String , category3_id:String , create_time:String, var category3_name:String, var spu_name:String, var tm_name:String )1
2
3
4
5
6
7
8
9
10
11
# 采集 Kafka 中维表数据到 Hbase 对应的表中
采集 Kafka 中品牌数据到 Hbase
object BaseTrademarkApp { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("BaseTrademarkApp") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topic = "ods_base_trademark"; val groupId = "dim_base_trademark_group" ///////////////////// 偏移量处理/////////////////////////// val offset: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic,groupId) var inputDstream: InputDStream[ConsumerRecord[String, String]] = null // 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用 kafka 读出默认最新的数据 if (offset != null && offset.size > 0) { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offset, groupId) } else { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId) } //取得偏移量步长 var offsetRanges: Array[OffsetRange] = null val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] = inputDstream.transform { rdd =>{ offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd } } val objectDstream: DStream[BaseTrademark] = inputGetOffsetDstream.map { record =>{ val jsonStr: String = record.value() val obj: BaseTrademark = JSON.parseObject(jsonStr, classOf[BaseTrademark]) obj } } import org.apache.phoenix.spark._ //保存到 Hbase objectDstream.foreachRDD{rdd=> rdd.saveToPhoenix("GMALL2020_BASE_TRADEMARK",Seq("ID", "TM_NAME" ) ,new Configuration,Some("ha01,ha02,ha03:2181")) OffsetManagerUtil.saveOffset(topic,groupId, offsetRanges) } ssc.start() ssc.awaitTermination() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45采集 Kafka 中分类数据到 Hbase
object BaseCategory3App { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("BaseCategory3App") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topic = "ods_base_category3"; val groupId = "dim_base_category3_group" ///////////////////// 偏移量处理/////////////////////////// val offset: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId) var inputDstream: InputDStream[ConsumerRecord[String, String]] = null // 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用 kafka 读出默认最新的数据 if (offset != null && offset.size > 0) { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offset, groupId) } else { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId) } //取得偏移量步长 var offsetRanges: Array[OffsetRange] = null val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] = inputDstream.transform { rdd => offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd } //转换结构 val objectDstream: DStream[BaseCategory3] = inputGetOffsetDstream.map { record => { val jsonStr: String = record.value() val obj: BaseCategory3 = JSON.parseObject(jsonStr, classOf[BaseCategory3]) obj } } //保存到 Hbase import org.apache.phoenix.spark._ objectDstream.foreachRDD { rdd => { rdd.saveToPhoenix("GMALL2020_BASE_CATEGORY3", Seq("ID", "NAME", "CATEGORY2_ID") , new Configuration, Some("ha01,ha02,ha03:2181")) OffsetManagerUtil.saveOffset(topic, groupId, offsetRanges) } } ssc.start() ssc.awaitTermination() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47采集 Kafka 中 Spu 数据到 Hbase
object SpuInfoApp { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("SpuInfoApp") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topic = "ods_spu_info"; val groupId = "dim_spu_info_group" ///////////////////// 偏移量处理/////////////////////////// val offset: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId) var inputDstream: InputDStream[ConsumerRecord[String, String]] = null // 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用 kafka 读出默认最新的数据 if (offset != null && offset.size > 0) { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offset, groupId) } else { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId) } //取得偏移量步长 var offsetRanges: Array[OffsetRange] = null val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] = inputDstream.transform { rdd =>{ offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd } } //转换结构 val objectDstream: DStream[SpuInfo] = inputGetOffsetDstream.map { record =>{ val jsonStr: String = record.value() val obj: SpuInfo = JSON.parseObject(jsonStr, classOf[SpuInfo]) obj } } //保存到 Hbase import org.apache.phoenix.spark._ objectDstream.foreachRDD{rdd=> rdd.saveToPhoenix("GMALL2020_SPU_INFO",Seq("ID", "SPU_NAME" ) ,new Configuration,Some("ha01,ha02,ha03:2181")) OffsetManagerUtil.saveOffset(topic,groupId, offsetRanges) } ssc.start() ssc.awaitTermination() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46采集 Kafka 中商品 Sku 数据到 Hbase
object SkuInfoApp { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("SkuInfoApp") val ssc = new StreamingContext(sparkConf, Seconds(5)) val topic = "ods_sku_info"; val groupId = "dim_sku_info_group" ///////////////////// 偏移量处理/////////////////////////// val offset: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(topic, groupId) var inputDstream: InputDStream[ConsumerRecord[String, String]] = null // 判断如果从 redis 中读取当前最新偏移量 则用该偏移量加载 kafka 中的数据 否则直接用 kafka 读出默认最新的数据 if (offset != null && offset.size > 0) { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offset, groupId) } else { inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId) } //取得偏移量步长 var offsetRanges: Array[OffsetRange] = null val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] = inputDstream.transform { rdd =>{ offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges rdd } } //结构转换 val objectDstream: DStream[SkuInfo] = inputGetOffsetDstream.map { record => { val jsonStr: String = record.value() val obj: SkuInfo = JSON.parseObject(jsonStr, classOf[SkuInfo]) obj } } //商品和品牌、分类、Spu 先进行关联 val skuInfoDstream: DStream[SkuInfo] = objectDstream.transform { rdd =>{ if(rdd.count()>0){ //tm_name val tmSql = "select id ,tm_name from gmall2020_base_trademark" val tmList: List[JSONObject] = PhoenixUtil.queryList(tmSql) val tmMap: Map[ String, JSONObject] = tmList.map(jsonObj => (jsonObj.getString("ID"), jsonObj)).toMap //category3 val category3Sql = "select id ,name from gmall2020_base_category3" //driver 周期性执行 val category3List: List[JSONObject] = PhoenixUtil.queryList(category3Sql) val category3Map: Map[String, JSONObject] = category3List.map(jsonObj => (jsonObj.getString("ID"), jsonObj)).toMap // spu val spuSql = "select id ,spu_name from gmall2020_spu_info" // spu val spuList: List[JSONObject] = PhoenixUtil.queryList(spuSql) val spuMap: Map[String, JSONObject] = spuList.map(jsonObj => (jsonObj.getString("ID"), jsonObj)).toMap // 汇总到一个 list 广播这个 map val dimList = List[Map[String, JSONObject]](category3Map,tmMap,spuMap) val dimBC: Broadcast[List[Map[String, JSONObject]]] = ssc.sparkContext.broadcast(dimList) val skuInfoRDD: RDD[SkuInfo] = rdd.mapPartitions { skuInfoItr =>{ //ex val dimList: List[Map[String, JSONObject]] = dimBC.value//接收 bc val category3Map: Map[String, JSONObject] = dimList(0) val tmMap: Map[String, JSONObject] = dimList(1) val spuMap: Map[String, JSONObject] = dimList(2) val skuInfoList: List[SkuInfo] = skuInfoItr.toList for (skuInfo <- skuInfoList) { val category3JsonObj: JSONObject = category3Map.getOrElse(skuInfo.category3_id , null) //从 map 中寻值 if (category3JsonObj != null) { skuInfo.category3_name = category3JsonObj.getString("NAME") } val tmJsonObj: JSONObject = tmMap.getOrElse(skuInfo.tm_id , null) //从 map 中寻值 if (tmJsonObj != null) { skuInfo.tm_name = tmJsonObj.getString("TM_NAME") } val spuJsonObj: JSONObject = spuMap.getOrElse(skuInfo.spu_id , null) //从 map 中寻值 if (spuJsonObj != null) { skuInfo.spu_name = spuJsonObj.getString("SPU_NAME") } } skuInfoList.toIterator } } skuInfoRDD }else{ rdd } } } //保存到 Hbase import org.apache.phoenix.spark._ skuInfoDstream.foreachRDD{ rdd=>{ rdd.saveToPhoenix( "GMALL2020_SKU_INFO", Seq("ID", "SPU_ID","PRICE","SKU_NAME","TM_ID","CATEGORY3_ID","CREATE_TIME","CATEGORY3_NAME","SPU_NAME","TM_NAME" ) ,new Configuration, Some("ha01,ha02,ha03:2181")) OffsetManagerUtil.saveOffset(topic,groupId, offsetRanges) } } ssc.start() ssc.awaitTermination() } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
# 订单明细事实表和 Sku 维度关联
OrderDetailApp 中添加如下代码:
//订单明细事实表与商品维表数据关联 品牌 分类 spu
val orderDetailWithSkuDstream: DStream[OrderDetail] =
orderDetailDstream.mapPartitions {
orderDetailItr =>{
val orderDetailList: List[OrderDetail] = orderDetailItr.toList
if(orderDetailList.size>0) {
val skuIdList: List[Long] = orderDetailList.map(_.sku_id)
val sql = s"select id ,tm_id,spu_id,category3_id,tm_name ,spu_name,category3_name from gmall2020_sku_info where id in ('${skuIdList.mkString("','")}')"
val skuJsonObjList: List[JSONObject] = PhoenixUtil.queryList(sql)
val skuJsonObjMap: Map[Long, JSONObject] = skuJsonObjList.map(skuJsonObj
=> (skuJsonObj.getLongValue("ID"), skuJsonObj)).toMap
for (orderDetail <- orderDetailList) {
val skuJsonObj: JSONObject = skuJsonObjMap.getOrElse(orderDetail.sku_id,
null)
orderDetail.spu_id = skuJsonObj.getLong("SPU_ID")
orderDetail.spu_name = skuJsonObj.getString("SPU_NAME")
orderDetail.tm_id = skuJsonObj.getLong("TM_ID")
orderDetail.tm_name = skuJsonObj.getString("TM_NAME")
orderDetail.category3_id = skuJsonObj.getLong("CATEGORY3_ID")
orderDetail.category3_name = skuJsonObj.getString("CATEGORY3_NAME")
}
}
orderDetailList.toIterator
}
}
orderDetailWithSkuDstream.print(10000)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 初始化品牌、商品分类、SPU、SKU
jps
bin/maxwell-bootstrap --user maxwell --password maxwell --host ha01 --database gmall2020 --table base_category3 --client_id maxwell_1
bin/maxwell-bootstrap --user maxwell --password maxwell --host ha01 --database gmall2020 --table spu_info --client_id maxwell_1
bin/maxwell-bootstrap --user maxwell --password maxwell --host ha01 --database gmall2020 --table sku_info --client_id maxwell_1
2
3
4
5
6
7
# 订单明细写入 Kafka(DWD 层)
# OrderDetailApp 后面添加如下代码
// 将关联后的订单明细宽表写入到 kafka 中
orderDetailWithSkuDstream.foreachRDD{
rdd=>{
rdd.foreach{
orderDetail=>{
MyKafkaSink.send("dwd_order_detail",
JSON.toJSONString(orderDetail,new SerializeConfig(true)))
}
}
OffsetManagerUtil.saveOffset(topic,groupId,offsetRanges)
}
}
2
3
4
5
6
7
8
9
10
11
12
# 订单写入 Kafka(DWD 层)
# OrderInfoApp 后面添加如下代码
//--------------3.2 将订单信息写入到 ES 中-----------------
rdd.foreachPartition {
orderInfoItr =>{
val orderInfoList: List[(String,OrderInfo)] =
orderInfoItr.toList.map(orderInfo => (orderInfo.id.toString,orderInfo))
val dateStr: String = new SimpleDateFormat("yyyyMMdd").format(new Date())
ESUtil.bulkInsert(orderInfoList, "gmall2020_order_info_" + dateStr)
//3.2 将订单信息推回 kafka 进入下一层处理 主题: dwd_order_info
for ((id,orderInfo) <- orderInfoList) {
//fastjson 要把 scala 对象包括 caseclass 转 转 json 字符串 需要加入,new SerializeConfig(true)
MyKafkaSink.send("dwd_order_info",
JSON.toJSONString(orderInfo,new SerializeConfig(true)))
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 双流合并实现
除了事实表与维表进行合并形成宽表,还需要事实表与事实表进行合并形成更大的宽表。
# 双流合并的问题
由于订单流和订单明细流,两个流的数据是独立保存,独立消费,很有可能同一业务的数据,分布在不同的批次。因为 join 算子只 join 同一批次的数据。如果只用简单的 join 流方式,会丢失掉不同批次的数据。
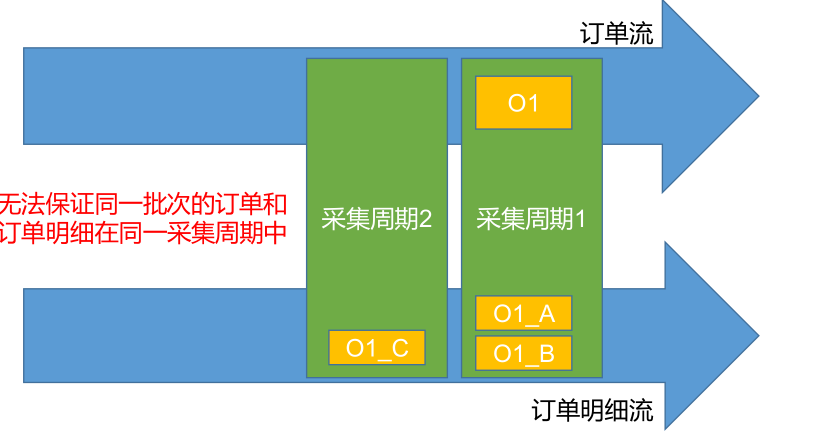
# 解决策略
# 通过缓存
两个流做满外连接因为网络延迟等关系,不能保证每个窗口中的数据 key 都能匹配上,这样势必会出现三种情况:(Some,Some),(None,Some),(Some,None),根据这三种情况
下面做一下详细解析:
(Some,Some)
1 号流和 2 号流中 key 能正常进行逻辑运算,但是考虑到 2 号流后续可能会有剩下的数据到来,所以需要将 1 号流中的 key 保存到 redis,以等待接下来的数据
(None,Some)
找不到 1 号流中对应 key 的数据,需要去 redis 中查找 1 号流的缓存,如果找不到,则缓存起来,等待 1 号流
(Some,None)
找不到 2 号流中的数据,需要将 key 保存到 redis,以等待接下来的数据,并且去 reids中找 2 号流的缓存,如果有,则 join,然后删除 2 号流的缓存
# 通过滑动窗口+数据去重
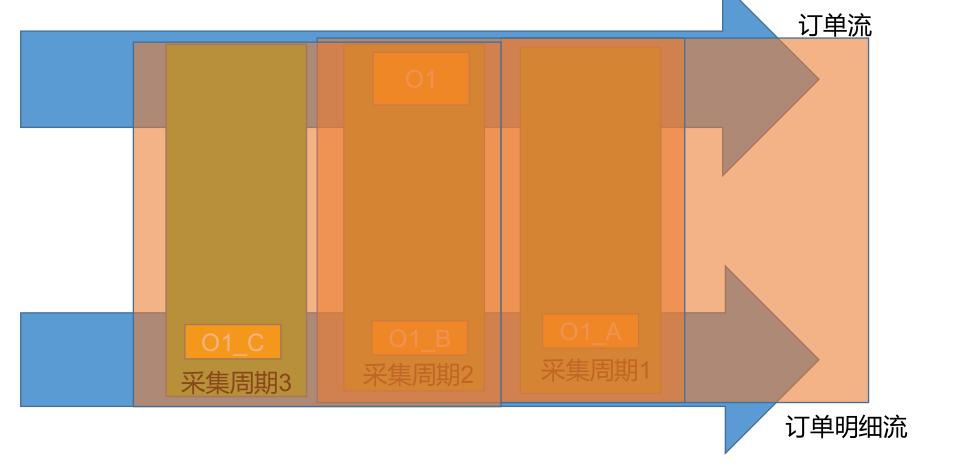
# 双流 Join 处理代码
创建 OrderWide 样例类,用于封装订单以及订单明细信息
case class OrderWide(
var order_detail_id: Long = 0L,
var order_id: Long = 0L,
var order_status: String = null,
var create_time: String = null,
var user_id: Long = 0L,
var sku_id: Long = 0L,
var sku_price: Double = 0D,
var sku_num: Long = 0L,
var sku_name: String = null,
var benefit_reduce_amount: Double = 0D,
var feight_fee: Double = 0D,
var original_total_amount: Double = 0D, //原始总金额 = 明细 Σ 个数*单价
var final_total_amount: Double = 0D, //实际付款金额 = 原始购买金额-优惠减免 金额+运费
//分摊金额
var final_detail_amount: Double = 0D,
//首单
var if_first_order: String = null,
//主表维度 : 省市 , 年龄段 性别
var province_name: String = null,
var province_area_code: String = null,
var user_age_group: String = null,
var user_gender: String = null,
var dt: String = null,
// 从表的维度 spu,品牌,品类
var spu_id: Long = 0L,
var tm_id: Long = 0L,
var category3_id: Long = 0L,
var spu_name: String = null,
var tm_name: String = null,
var category3_name: String = null
) {
def this(orderInfo: OrderInfo, orderDetail: OrderDetail) {
this
mergeOrderInfo(orderInfo)
mergeOrderDetail(orderDetail)
}
def mergeOrderInfo(orderInfo: OrderInfo): Unit = {
if (orderInfo != null) {
this.order_id = orderInfo.id
this.order_status = orderInfo.order_status
this.create_time = orderInfo.create_time
this.dt = orderInfo.create_date
this.benefit_reduce_amount = orderInfo.benefit_reduce_amount
this.original_total_amount = orderInfo.original_total_amount
this.feight_fee = orderInfo.feight_fee
this.final_total_amount = orderInfo.final_total_amount
this.province_name = orderInfo.province_name
this.province_area_code = orderInfo.province_area_code
this.user_age_group = orderInfo.user_age_group
this.user_gender = orderInfo.user_gender
this.if_first_order = orderInfo.if_first_order
this.user_id = orderInfo.user_id
}
}
def mergeOrderDetail(orderDetail: OrderDetail): Unit = {
if (orderDetail != null) {
this.order_detail_id = orderDetail.id
this.sku_id = orderDetail.sku_id
this.sku_name = orderDetail.sku_name
this.sku_price = orderDetail.order_price
this.sku_num = orderDetail.sku_num
this.spu_id = orderDetail.spu_id
this.tm_id = orderDetail.tm_id
this.category3_id = orderDetail.category3_id
this.spu_name = orderDetail.spu_name
this.tm_name = orderDetail.tm_name
this.category3_name = orderDetail.category3_name
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
# 在 DWS 中创建 OrderWideApp 接收数据
package top.damoncai.rtdw.dws
import com.alibaba.fastjson.{JSON, JSONArray, JSONObject}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import redis.clients.jedis.Jedis
import top.damoncai.rtdw.bean.{OrderDetail, OrderInfo, OrderWide}
import top.damoncai.rtdw.utils.{MyKafkaSink, MyKafkaUtil, MyRedisUtil, OffsetManagerUtil}
import java.lang
import scala.collection.mutable.ListBuffer
object OrderWideApp {
def main(args: Array[String]): Unit = {
//双流 订单主表 订单明细表 偏移量 双份
val sparkConf: SparkConf = new
SparkConf().setMaster("local[4]").setAppName("OrderWideApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val orderInfoGroupId = "dws_order_info_group"
val orderInfoTopic = "dwd_order_info"
val orderDetailGroupId = "dws_order_detail_group"
val orderDetailTopic = "dwd_order_detail"
//从 redis 中读取偏移量 (启动执行一次)
val orderInfoOffsetMapForKafka: Map[TopicPartition, Long] =
OffsetManagerUtil.getOffset(orderInfoTopic, orderInfoGroupId)
val orderDetailOffsetMapForKafka: Map[TopicPartition, Long] =
OffsetManagerUtil.getOffset(orderDetailTopic, orderDetailGroupId)
//根据订单偏移量,从 Kafka 中获取订单数据
var orderInfoRecordInputDstream: InputDStream[ConsumerRecord[String,
String]] = null
if (orderInfoOffsetMapForKafka != null && orderInfoOffsetMapForKafka.size >
0) { //根据是否能取到偏移量来决定如何加载 kafka 流
orderInfoRecordInputDstream = MyKafkaUtil.getKafkaStream(orderInfoTopic,
ssc, orderInfoOffsetMapForKafka, orderInfoGroupId)
} else {
orderInfoRecordInputDstream = MyKafkaUtil.getKafkaStream(orderInfoTopic,
ssc, orderInfoGroupId)
}
//根据订单明细偏移量,从 Kafka 中获取订单明细数据
var orderDetailRecordInputDstream: InputDStream[ConsumerRecord[String,
String]] = null
if (orderDetailOffsetMapForKafka != null &&
orderDetailOffsetMapForKafka.size > 0) { //根据是否能取到偏移量来决定如何加载 kafka 流
orderDetailRecordInputDstream =
MyKafkaUtil.getKafkaStream(orderDetailTopic, ssc, orderDetailOffsetMapForKafka,
orderDetailGroupId)
} else {
orderDetailRecordInputDstream =
MyKafkaUtil.getKafkaStream(orderDetailTopic, ssc, orderDetailGroupId)
}
//从流中获得本批次的 订单偏移量结束点(每批次执行一次)
var orderInfoOffsetRanges: Array[OffsetRange] = null //周期性储存了当前批次偏移量的变化状态,重要的是偏移量结束点
val orderInfoInputGetOffsetDstream: DStream[ConsumerRecord[String, String]]
= orderInfoRecordInputDstream.transform { rdd => //周期性在 driver 中执行
orderInfoOffsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
//从流中获得本批次的 订单明细偏移量结束点(每批次执行一次)
var orderDetailOffsetRanges: Array[OffsetRange] = null //周期性储存了当前批次偏移量的变化状态,重要的是偏移量结束点
val orderDetailInputGetOffsetDstream: DStream[ConsumerRecord[String,
String]] = orderDetailRecordInputDstream.transform { rdd => //周期性在 driver 中执行
orderDetailOffsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
//提取订单数据
val orderInfoDstream: DStream[OrderInfo] =
orderInfoInputGetOffsetDstream.map {
record =>{
val jsonString: String = record.value()
val orderInfo: OrderInfo = JSON.parseObject(jsonString,
classOf[OrderInfo])
orderInfo
}
}
//提取明细数据
val orderDetailDstream: DStream[OrderDetail] =
orderDetailInputGetOffsetDstream.map {
record =>{
val jsonString: String = record.value()
val orderDetail: OrderDetail = JSON.parseObject(jsonString,
classOf[OrderDetail])
orderDetail
}
}
orderInfoDstream.print(1000)
orderDetailDstream.print(1000)
//直接 join:无法保证同一批次的订单和订单明细在同一采集周期中
//转换订单和订单明细结构为 k-v 类型,然后进行 join
//val orderInfoWithKeyDstream: DStream[(Long, OrderInfo)] =
orderInfoDstream.map(orderInfo=>(orderInfo.id,orderInfo))
//val orderDetailWithKeyDstream: DStream[(Long, OrderDetail)] =
orderDetailDstream.map(orderDetail=>(orderDetail.order_id,orderDetail))
//val joinedDstream: DStream[(Long, (OrderInfo, OrderDetail))] = orderInfoWithKeyDstream.join(orderDetailWithKeyDstream,4)
//-----------开窗 + 去重完成 join-------------
//开窗 指定窗口大小和滑动步长
val orderInfoWindowDstream: DStream[OrderInfo] =
orderInfoDstream.window(Seconds(50), Seconds(5))
val orderDetailWindowDstream: DStream[OrderDetail] =
orderDetailDstream.window(Seconds(50), Seconds(5))
// join
val orderInfoWithKeyDstream: DStream[(Long, OrderInfo)] =
orderInfoWindowDstream.map(
orderInfo=>{
(orderInfo.id,orderInfo)
}
)
val orderDetailWithKeyDstream: DStream[(Long, OrderDetail)] =
orderDetailWindowDstream.map(
orderDetail=>{
(orderDetail.order_id,orderDetail)
}
)
val joinedDstream: DStream[(Long, (OrderInfo, OrderDetail))] =
orderInfoWithKeyDstream.join(orderDetailWithKeyDstream,4)
// 去重 数据统一保存到 redis ? type? set api? sadd key ? order_join:[orderId] value ? orderDetailId expire : 60*10
// sadd 返回如果 0 过滤掉
val orderWideDstream: DStream[OrderWide] = joinedDstream.mapPartitions {
tupleItr => {
val jedis: Jedis = MyRedisUtil.getJedisClient
val orderWideList: ListBuffer[OrderWide] = ListBuffer[OrderWide]()
for ((orderId, (orderInfo, orderDetail)) <- tupleItr) {
val key = "order_join:"+orderId
val ifNotExisted: lang.Long = jedis.sadd(key, orderDetail.id.toString)
jedis.expire(key, 600)
//合并宽表
if (ifNotExisted == 1L) {
orderWideList.append(new OrderWide(orderInfo, orderDetail))
}
}
jedis.close()
orderWideList.toIterator
}
}
orderWideDstream.print(1000)
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
# 订单明细实付金额分摊实现
OrderWideApp中添加
//------------实付分摊计算--------------
val orderWideWithSplitDStream: DStream[OrderWide] =
orderWideDstream.mapPartitions {
orderWideItr =>{
//建连接
val jedis: Jedis = MyRedisUtil.getJedisClient
val orderWideList: List[OrderWide] = orderWideItr.toList
println("分区 orderIds:" + orderWideList.map(_.order_id).mkString(","))
//迭代
for (orderWide <- orderWideList) {
// 从 Redis 中获取原始金额累计
// redis type? string key? order_origin_sum:[order_id] value? Σ其他的明细(个数*单价)
val originSumKey = "order_origin_sum:" + orderWide.order_id
var orderOriginSum: Double = 0D
val orderOriginSumStr = jedis.get(originSumKey)
//从 redis 中取出来的任何值都要进行判空
if (orderOriginSumStr != null && orderOriginSumStr.size > 0) {
orderOriginSum = orderOriginSumStr.toDouble
}
//从 Reids 中获取分摊金额累计
// redis type? string key? order_split_sum:[order_id] value? Σ其他的明细的分摊金额
val splitSumKey = "order_split_sum:" + orderWide.order_id
var orderSplitSum: Double = 0D
val orderSplitSumStr: String = jedis.get(splitSumKey)
if (orderSplitSumStr != null && orderSplitSumStr.size > 0) {
orderSplitSum = orderSplitSumStr.toDouble
}
// 判断是否为最后一笔
// 如果当前的一笔 个数*单价 == 原始总金额 - Σ其他的明细(个数*单价)
// 个数 单价 原始金额 可以从 orderWide 取到,明细汇总值已从 Redis 取出
//如果等式成立 说明该笔明细是最后一笔 (如果当前的一笔 个数*单价== 原始总金额- Σ其他的明细(个数*单价))
val detailAmount = orderWide.sku_price * orderWide.sku_num
if (detailAmount == orderWide.original_total_amount - orderOriginSum)
{
// 分摊计算公式 :减法公式 分摊金额= 实际付款金额- Σ其他的明细的分摊金额 (减 法,适用最后一笔明细)
// 实际付款金额 在 orderWide 中,要从 redis 中取得 Σ其他的明细的分摊金额
orderWide.final_detail_amount =
Math.round( (orderWide.final_total_amount - orderSplitSum)*100D)/100D
} else {
//如果不成立
// 分摊计算公式: 乘除法公式: 分摊金额= 实际付款金额 *(个数*单价) / 原始总金额 (乘除法,适用非最后一笔明细)
// 所有计算要素都在 orderWide 中,直接计算即可
orderWide.final_detail_amount =
Math.round( (orderWide.final_total_amount * detailAmount /
orderWide.original_total_amount)*100D)/100D
}
// 分摊金额计算完成以后
// 将本次计算的分摊金额 累计到 redis Σ其他的明细的分摊金额
val newOrderSplitSum = (orderWide.final_detail_amount +
orderSplitSum).toString
jedis.setex(splitSumKey, 600, newOrderSplitSum)
// 应付金额(单价*个数) 要累计到 Redis Σ其他的明细(个数*单价)
val newOrderOriginSum = (detailAmount + orderOriginSum).toString
jedis.setex(originSumKey, 600, newOrderOriginSum)
}
// 关闭 redis
jedis.close()
//返回一个计算完成的 list 的迭代器
orderWideList.toIterator
}
}
orderWideWithSplitDStream.map{
orderWide=>JSON.toJSONString(orderWide,new SerializeConfig(true))
}.print(1000)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 将 订 单 及 明 细 保 存 到ClickHouse 实现
# 在 ha01 的 ClickHouse 中建表
create table t_order_wide_2020 (
order_detail_id UInt64,
order_id UInt64,
order_status String,
create_time DateTime,
user_id UInt64,
sku_id UInt64,
sku_price Decimal64(2),
sku_num UInt64,
sku_name String,
benefit_reduce_amount Decimal64(2),
original_total_amount Decimal64(2),
feight_fee Decimal64(2),
final_total_amount Decimal64(2),
final_detail_amount Decimal64(2),
if_first_order String,
province_name String,
province_area_code String,
user_age_group String,
user_gender String,
dt Date,
spu_id UInt64,
tm_id UInt64,
category3_id UInt64,
spu_name String,
tm_name String,
category3_name String
)engine =ReplacingMergeTree(create_time)
partition by dt
primary key (order_detail_id)
order by (order_detail_id );
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# Idea 中编写程序
# POM
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
</exclusion>
</exclusions>
</dependency>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# OrderWideApp 添加写到 ClickHouse 代码
//将数据保存到 ClickHouse
val sparkSession = SparkSession.builder()
.appName("order_detail_wide_spark_app")
.getOrCreate()
import sparkSession.implicits._
orderWideWithSplitDStream.foreachRDD{
rdd=>{
val df: DataFrame = rdd.toDF()
df.write.mode(SaveMode.Append)
.option("batchsize", "100")
.option("isolationLevel", "NONE") // 设置事务
.option("numPartitions", "4") // 设置并发
.option("driver","ru.yandex.clickhouse.ClickHouseDriver")
.jdbc("jdbc:clickhouse://ha01:8123/default","t_order_wide_2020",new Properties())
//提交偏移量
OffsetManagerUtil.saveOffset(orderInfoTopic,orderInfoGroupId,orderInfoOffsetRanges)
OffsetManagerUtil.saveOffset(orderDetailTopic,orderDetailGroupId,orderDetailOffsetRanges)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# ADS 聚合
# 业务流程图
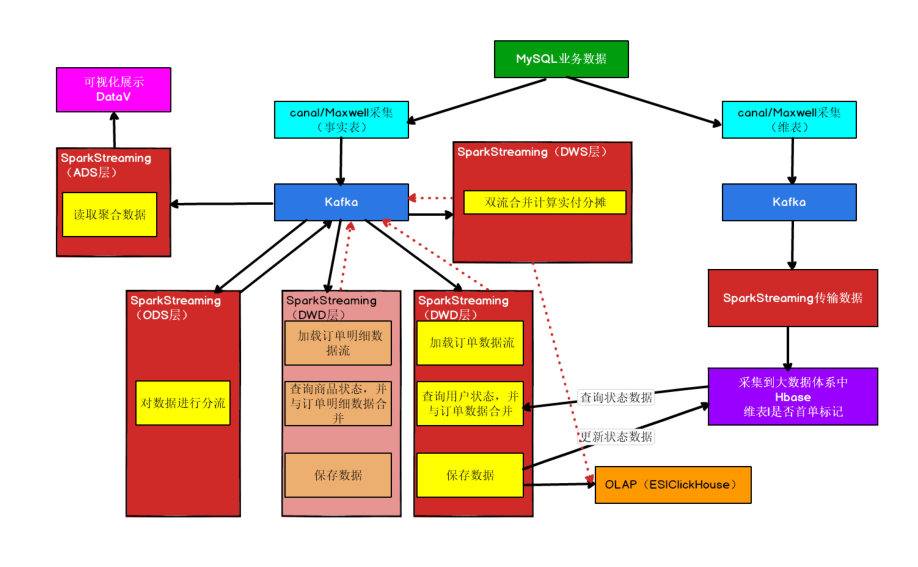
ads 层,主要是根据各种报表及可视化来生成统计数据。通常这些报表及可视化都是基于某些维度的汇总统计
统计表分为三个部分:时间点、维度、度量
时间点:即统计结果产生的时间,或者本批次数据中业务日期最早的时间。
维度:统计维度,比如地区、商品名称、性别
度量:汇总的数据,比如金额、数量
每个批次进行一次聚合,根据数据的及时性要求,可以调整批次的时间长度,将聚合后的结果一波一波的存放到数据库中。
# 数据库的选型与难点
聚合数据本身并不麻烦,利用 reducebykey 或者 groupbykey 都可以聚合,但是麻烦的是实现精确性一次消费。因为聚合数据不是明细,没有确定的主键,所以没有办法实现幂等。那么如果想实现精确一次消费,就要考虑利用关系型数据库的事务处理。
用本地事务管理最大的问题是数据保存操作要放在 driver 端变成单线程操作,性能降低。 但是由于本业务保存的是聚合后的数据所以数据量并不大,即使单线程保存也是可以接受的,因此数据库和偏移量选用 mysql 进行保存。
# 代码实现
在 gmall2020-realtime 中编写代码
pom
<!-- scala 操作 JDBC 小工具,方便对事务进行处理 --> <dependency> <groupId>org.scalikejdbc</groupId> <artifactId>scalikejdbc_2.12</artifactId> <version>3.4.0</version> </dependency> <!-- scalikejdbc-config_2.11 --> <dependency> <groupId>org.scalikejdbc</groupId> <artifactId>scalikejdbc-config_2.12</artifactId> <version>3.4.0</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17数据库准备并创建索引表
CREATE TABLE `offset_2020` ( `group_id` varchar(200) NOT NULL, `topic` varchar(200) NOT NULL, `partition_id` int(11) NOT NULL, `topic_offset` bigint(20) DEFAULT NULL, PRIMARY KEY (`group_id`,`topic`,`partition_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;1
2
3
4
5
6
7创建保存品牌聚合结果的表
CREATE TABLE `trademark_amount_stat` ( `stat_time` datetime, `trademark_id` varchar(20), `trademark_name` varchar(200), `amount` decimal(16,2) , PRIMARY KEY (`stat_time`,`trademark_id`,`trademark_name`) )ENGINE=InnoDB DEFAULT CHARSET=utf8;1
2
3
4
5
6
7
8
# 创建相关工具类
创建查询 MySQL 数据库的工具类 MySQLUtil
object MySQLUtil { def main(args: Array[String]): Unit = { val list: List[ JSONObject] = queryList("select * from offset_2020") println(list) } def queryList(sql:String):List[JSONObject]={ Class.forName("com.mysql.jdbc.Driver") val resultList: ListBuffer[JSONObject] = new ListBuffer[ JSONObject]() val conn: Connection = DriverManager.getConnection( "jdbc:mysql://hadoop202:3306/gmall2020_rs?characterEncoding=utf-8&useSSL=false", "root", "123456") val stat: Statement = conn.createStatement println(sql) val rs: ResultSet = stat.executeQuery(sql) val md: ResultSetMetaData = rs.getMetaData while ( rs.next ) { val rowData = new JSONObject(); for (i <-1 to md.getColumnCount ) { rowData.put(md.getColumnName(i), rs.getObject(i)) } resultList+=rowData } stat.close() conn.close() resultList.toList } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28读取 MySQL 中偏移量的工具类 OffsetManagerM
object OffsetManagerM { /** * 从 Mysql 中读取偏移量 * @param consumerGroupId * @param topic * @return */ def getOffset(topic: String, consumerGroupId: String): Map[TopicPartition, Long] = { val sql=" select group_id,topic,topic_offset,partition_id from offset_2020" + " where topic='"+topic+"' and group_id='"+consumerGroupId+"'" val jsonObjList: List[JSONObject] = MySQLUtil.queryList(sql) val topicPartitionList: List[(TopicPartition, Long)] = jsonObjList.map { jsonObj =>{ val topicPartition: TopicPartition = new TopicPartition(topic, jsonObj.getIntValue("partition_id")) val offset: Long = jsonObj.getLongValue("topic_offset") (topicPartition, offset) } } val topicPartitionMap: Map[TopicPartition, Long] = topicPartitionList.toMap topicPartitionMap } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22在 OrderWideApp 中将数据写回 Kafka
// 将数据写回到 Kafka rdd.foreach{orderWide=> MyKafkaSink.send("dws_order_wide", JSON.toJSONString(orderWide,new SerializeConfig(true))) }1
2
3
4
# 关于本地事务保存 MySql
我们在处理事务的时候引用了一个 scala 的 MySQL 工具:scalikeJdbc
读取配置文件
默认从 classpath 下读取 application.conf,获取数据库连接信息,所以我们在resources 下创建 application.conf 文件
db.default.driver="com.mysql.jdbc.Driver" db.default.url="jdbc:mysql://ha01/gmall2020_rs?characterE ncoding=utf-8&useSSL=false" db.default.user="root" db.default.password="123456"1
2
3
4
5程序中加载配置
DBs.setup()1本地事务提交数据
凡是在 DB. localTx (implicit session => { } )中的 SQL 全部被本地事务进行关联,一条失败全部回滚
DB.localTx( implicit session => { SQL1 SQL2 } )1
2
3
4
5
6
# TrademarkStatApp(ads)
package top.damoncai.rtdw.ads
import java.text.SimpleDateFormat
import java.util.Date
import com.alibaba.fastjson.JSON
import com.atguigu.gmall.realtime.bean.OrderWide
import com.atguigu.gmall.realtime.utils.{MyKafkaUtil, OffsetManagerM}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scalikejdbc.{DB, SQL}
import scalikejdbc.config.DBs
import top.damoncai.rtdw.bean.OrderWide
import top.damoncai.rtdw.utils.{MyKafkaUtil, OffsetManagerM}
import scala.collection.mutable.ListBuffer
/**
* Author: Felix
* Desc: 从 Kafka 中读取 dws 层数据,并对其进行聚合处理,写回到 MySQL(ads 层 )
*/
object TrademarkStatApp {
def main(args: Array[String]): Unit = {
// 加载流
val sparkConf: SparkConf = new
SparkConf().setMaster("local[4]").setAppName("TrademarkStatApp")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "ads_trademark_stat_group"
val topic = "dws_order_wide";
//从 Mysql 中读取偏移量
val offsetMapForKafka: Map[TopicPartition, Long] = OffsetManagerM.getOffset(topic, groupId)
//把偏移量传递给 kafka ,加载数据流
var recordInputDstream: InputDStream[ConsumerRecord[String, String]] = null
if (offsetMapForKafka != null && offsetMapForKafka.size > 0) { //根据是否能取到偏移量来决定如何加载 kafka 流
recordInputDstream = MyKafkaUtil.getKafkaStream(topic, ssc,
offsetMapForKafka, groupId)
} else {
recordInputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
}
//从流中获得本批次的 偏移量结束点
var offsetRanges: Array[OffsetRange] = null
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] =
recordInputDstream.transform {
rdd =>{
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
}
//提取数据
val orderWideDstream: DStream[OrderWide] = inputGetOffsetDstream.map {
record =>{
val jsonString: String = record.value()
//订单处理 脱敏 换成特殊字符 直接去掉 转换成更方便操作的专用样例类
val orderWide: OrderWide = JSON.parseObject(jsonString, classOf[OrderWide])
orderWide
}
}
// 聚合
val trademarkAmountDstream: DStream[(String, Double)] =
orderWideDstream.map{
orderWide => {
(orderWide.tm_id + "_" + orderWide.tm_name, orderWide.final_detail_amount)
}
}
val tradermarkSumDstream: DStream[(String, Double)] =
trademarkAmountDstream.reduceByKey(_ + _)
tradermarkSumDstream.print(1000)
//存储数据以及偏移量到 MySQL 中,为了保证精准消费 我们将使用事务对存储数据和修改偏移量进行控制
/*//方式 1:单条插入
tradermarkSumDstream.foreachRDD {
rdd =>{
// 为了避免分布式事务,把 ex 的数据提取到 driver 中;因为做了聚合,所以可以直接将
Executor 的数据聚合到 Driver 端
val tmSumArr: Array[(String, Double)] = rdd.collect()
if (tmSumArr !=null && tmSumArr.size > 0) {
DBs.setup()
DB.localTx {
implicit session =>{
// 写入计算结果数据
val formator = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
for ((tm, amount) <- tmSumArr) {
val statTime: String = formator.format(new Date())
val tmArr: Array[String] = tm.split("_")
val tmId = tmArr(0)
val tmName = tmArr(1)
val amountRound: Double = Math.round(amount * 100D) / 100D
println("数据写入执行")
SQL("insert into
trademark_amount_stat(stat_time,trademark_id,trademark_name,amount)
values(?,?,?,?)")
.bind(statTime,tmId,tmName,amountRound).update().apply()
}
//throw new RuntimeException("测试异常")
// 写入偏移量
for (offsetRange <- offsetRanges) {
val partitionId: Int = offsetRange.partition
val untilOffset: Long = offsetRange.untilOffset
println("偏移量提交执行")
SQL("replace into offset_2020 values(?,?,?,?)").bind(groupId,
topic, partitionId, untilOffset).update().apply()
}
}
}
}
}
}*/
//方式 2:批量插入
tradermarkSumDstream.foreachRDD {
rdd =>{
// 为了避免分布式事务,把 ex 的数据提取到 driver 中;因为做了聚合,所以可以直接将Executor 的数据聚合到 Driver 端
val tmSumArr: Array[(String, Double)] = rdd.collect()
if (tmSumArr !=null && tmSumArr.size > 0) {
DBs.setup()
DB.localTx {
implicit session =>{
// 写入计算结果数据
val formator = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val dateTime: String = formator.format(new Date())
val batchParamsList: ListBuffer[Seq[Any]] = ListBuffer[Seq[Any]]()
for ((tm, amount) <- tmSumArr) {
val amountRound: Double = Math.round(amount * 100D) / 100D
val tmArr: Array[String] = tm.split("_")
val tmId = tmArr(0)
val tmName = tmArr(1)
batchParamsList.append(Seq(dateTime, tmId, tmName, amountRound))
}
//val params: Seq[Seq[Any]] = Seq(Seq("2020-08-01 10:10:10","101"," 品牌 1",2000.00),
// Seq("2020-08-01 10:10:10","102","品牌 2",3000.00))
//数据集合作为多个可变参数 的方法 的参数的时候 要加:_*
SQL("insert into trademark_amount_stat(stat_time,trademark_id,trademark_name,amount) values(?,?,?,?)")
.batch(batchParamsList.toSeq:_*).apply()
//throw new RuntimeException("测试异常")
// 写入偏移量
for (offsetRange <- offsetRanges) {
val partitionId: Int = offsetRange.partition
val untilOffset: Long = offsetRange.untilOffset
SQL("replace into offset_2020 values(?,?,?,?)").bind(groupId,
topic, partitionId, untilOffset).update().apply()
}
}
}
}
}
}
ssc.start()
ssc.awaitTermination()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150